
 EN
EN
In this blogpost, we show how one can use the SambaNova platform to develop a GPT 13B parameter model that can outperform a GPT 175B parameter model. We achieved greater than 10x efficiency by leveraging advanced ML techniques in pretraining, in-context learning, and data curation practices [1-8,10]. These ML capabilities are available to enterprise users through simple low-code APIs to make it easy for them to achieve better accuracy. Using these APIs, enterprise users can train and deploy models with full ownership and control on their data and model artifacts.
SambaNova’s GPT 13B model achieves comparable accuracy to the OpenAI 175B da-vinci-001 model for in-context learning scenarios and up-to 6% improved accuracy over the 175B da-vinci fine-tuning API for scenarios where some amount of tuning is required, but only minimal labeled data is available. We achieve this by using advanced training pipelines combined with the latest data curation practices and the latest in-context learning techniques [1-8,10]. This makes our pipeline useful in both the exploration and prototyping phase and the deployment and enhancement phase. We make this high quality pre-trained checkpoint available to our customers. We also enable our customers to train their own custom models to such high quality by providing the infrastructure, the tools, and the ML capabilities through simple APIs.
In the subsequent paragraphs, we discuss our approach towards training this GPT 13B model and the research papers that drove the critical decisions in our methodology around data collection, in-context learning, and low resource tuning.
Data Centric Approach to Pre-training
The recent theme of discussion within the NLP community has centered around data. Recent innovations in data practices have led to massive advances in how to extract the most out of a given corpus and to push the abilities of LLMs. To train our GPT 13B model, we use several advanced data centric approaches to create a high quality pre-training corpus, including, mixing of diverse datasets [1][2], data cleaning and data deduplication processes [3][4], using structural signals from the data for weak supervision [5], and instruction tuned and prompted datasets [6][7]. The methods, infrastructure, and the know-how to create these high quality pre-training corpora can be made available to our customers upon request.
Exploration, Prototyping, and In-Context Learning
To explore new tasks, in-context learning is a powerful technique. It allows rapid prototyping to determine whether LLMs can be deployed for your particular use case. Under this setting, we show how the same accuracy can be achieved as the 175B model from OpenAI using a much smaller SambaNova GPT 13B model.
We use 15 benchmarks that are available in standard LLM evaluation suites. These include text generation, classification, question answering, sentiment analysis, and entailment. All are essential for powering a variety of real world use cases, and showcase how our services provide a clear benefit. The names of these benchmarks can be found in Figure 1.
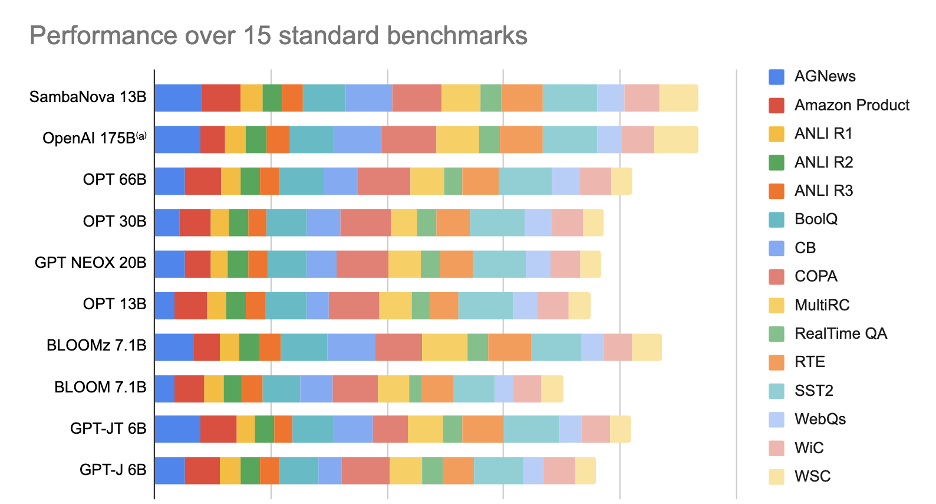
In Figure 1, we compare our 13B GPT model with OpenAI’s 175B numbers available in [9]a , as well as a selection of mainstream community checkpoints including Meta’s OPT and Big Science’s BLOOM. We use an in-context learning technique called “Ask me Anything” (AMA) prompting [10], to generate the few shot numbers for our model. Additionally, even with this advanced prompting technique, the cost of running the 13B GPT model is still less than that of the OpenAI 175B model. As we can see from the figure, on average, our 13B GPT model is iso-accuracy comparable to OpenAI’s 175B model, while outperforming a variety of publicly available checkpoints.
Deployment, Enhancement, and Low Resource Generative Fine-Tuning
While in-context learning allows one to rapidly prototype and understand the usefulness of a LLM for a particular task, eventually, some amount of fine-tuning is required to deploy the model robustly [8] in enterprise scenarios. Labeled data is hard to find in an enterprise setting. As a result, this fine-tuning needs to happen with a very limited amount of labeled data.
To measure the impact of SambaNova’s capabilities and its flexible training pipeline, we recreate common enterprise scenarios and test our 13B GPT model to see how well it performs. Informed by interactions with our customers, we created low resource versions of benchmarks that closely mimic enterprise datasets and real world use cases. Specifically, we sample 100 labeled examples for each class in the benchmark and use it to train our models. Additionally, we use the flexibility of our pipeline to unlock the potential of the unlabeled data for a task via self learningc. The benchmark and the associated results can be found in Table 1. We compare our 13B GPT model trained using our pipeline with the fine-tuned OpenAI’s 175B model using their latest fine-tuning APIb. As seen in the table, our model consistently outperforms OpenAI’s fine-tuned 175B model on every benchmark we evaluated.
| Dataset | Representative Enterprise Use Cases | SambaNova 13B GPT |
OpenAI Da-Vinci Fine-Tuning API |
| Finance NER | Document processing | 74.46 (F1) | 72.40 (F1) |
| MNLI | Contract Review | 64.93 (acc) | 60.2 (acc) |
| Dialogue Dataset | Call summarization | 68.29 (acc) 71.52 (weighted F1) |
61.11 (acc) 67.35 (weighted F1) |
Table 1: Fine-tuned results comparison using 100 labeled data for each task
The SambaNova differentiation
This blogpost demonstrates how the SambaNova platform can be used to create custom, state-of-the-art GPT models. This is achieved with a flexible pipeline that enables the most advanced techniques for pre-training, in-context learning, and generative tuning. These capabilities and the high quality checkpoints are both available for our customers to use. This enables them to build their own models, improve their models, or build on top of our checkpoints. In subsequent blog posts we will talk more about our results with instruction tuning, experience with self learning, and the breadth of our capabilities which allow you to explore a wide variety of community checkpoints.
——————
Acknowledgments
We thank Simran Arora, Avanika Narayan, Laurel Orr from Stanford Hazy Research Group for introducing the ASK ME ANYTHING PROMPTING (AMA) for in-context learning through their publication, and the helpful discussions with us.
[a] We use OpenAI paper numbers for this work. We want to compare zero shot and few shot numbers for the benchmarks which requires that the model has not seen the data from that benchmark during training. OpenAI’s paper numbers are the only definitive numbers that adhere to this requirement.
[b] Used the OpenAI finetuning API (https://beta.openai.com/docs/guides/fine-tuning). Capabilities similar to what is available as of 01/2023
[c] We use a simple version of self learning where we fine tune a GPT model on the 100 labeled dataset and use the trained model to create labels for the unlabeled dataset. We have explored more advanced self learning pipelines and while they help improve accuracy, we don’t discuss them here for simplicity. We will talk about how to use our platform to do self learning in a subsequent blog post.
References
[1] :The Pile: An 800GB Dataset of Diverse Text for Language Modeling
(https://arxiv.org/abs/2101.00027)
[2]: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
(https://arxiv.org/abs/1910.10683)
[3]: Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus (https://arxiv.org/pdf/2104.08758.pdf)
[4]: Deduplicating Training Data Makes Language Models Better (https://arxiv.org/abs/2107.06499)
[5]: reStructured Pre-training ( https://arxiv.org/abs/2206.11147 )
[6]: Scaling Instruction-Finetuned Language Models (https://arxiv.org/pdf/2210.11416.pdf )
[7]: Multitask Prompted Training Enables Zero-Shot Task Generalization
(https://arxiv.org/pdf/2110.08207.pdf)
[9] Language Models are Few-Shot Learners (https://arxiv.org/abs/2005.14165)
[10] Ask Me Anything: A simple strategy for prompting language models (https://arxiv.org/abs/2210.02441 )

