


Find out how SambaNova is driving AI innovation
Developers & Enterprise
Powers leading businesses with private, plug-and-play, and fast AI.
Learn more → Developers & EnterpriseGovernment & Public Sector
Gain secure, flexible, and fast AI inference for all nations.
Learn more → Government & Public SectorData Centers
Unlock new revenue streams by deploying AI in existing infrastructure.
Learn more → Data Centers
SambaNova Launches First Turnkey AI Inference Solution for Data Centers, Deployable in 90 Days

SambaNova Launches First Turnkey AI Inference Solution for Data Centers, Deployable in 90 Days
July 7, 2025
SambaNova Launches its AI Platform in AWS Marketplace

SambaNova Launches its AI Platform in AWS Marketplace
May 29, 2025
Why SambaNova's SN40L Chip is The Best for Inference
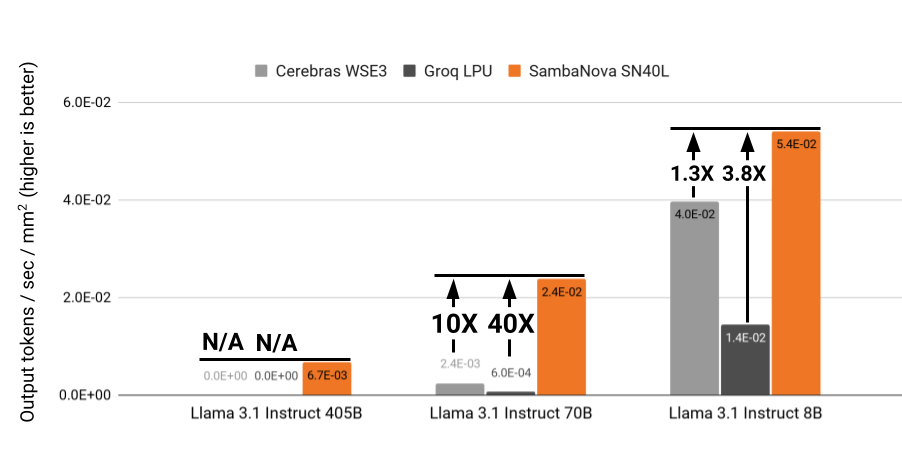
Why SambaNova's SN40L Chip is The Best for Inference
September 10, 2024