
 EN
EN
At SambaNova, we have been researching and developing methods to train long sequence size (SS) models on our platform. Training longer sequence models has become paramount to enabling a variety of business applications including summarizing long form documents, such as contracts or other legal documents, and answering questions on those documents. This is vital functionality for enterprises to incorporate generative AI into their business processes. A long sequence model also means it has a larger context window. More guiding examples can therefore be provided as part of the few-shot input prompt, leading to higher quality results.
As part of our effort to enable these business applications, we share some of our early results when training a 13 billion (B) parameter model at 8K sequence length. This approach has led to the SN-13B-8k-Instruct model, which outperforms leading long sequence open source models on long sequence size tasks.
Our average score on the long sequence benchmark suite derived from Scrolls is up to two points greater than other leading open source long sequence models – XGen from Salesforce, MPT-8K from MosaicML and LLAMA2-Chat from Meta. These models represent the current state-of-the-art open source alternatives for Long SS models. In addition, our results on the validation set of ZeroScrolls benchmark outperforms XGen, MPT and LLAMA-2 by as much as 10 points. Scrolls and ZeroScrolls are benchmarks released by Tel Aviv University and Meta which tests the ability of models to aggregate and compare information from long sequences.
SambaNova is committed to the open source community and we are releasing a checkpoint on Hugging Face for the community to use and test. This checkpoint was created primarily to develop long sequence capabilities and contribute a competitive long sequence model to the community. This is not meant to be used as a chat model. This methodology for long sequence model training will also be available for SambaNova Suite customers.
Training long SS models with SambaNova
METHODOLOGY
PRE-TRAINING
Curriculum Pre-training with Long Sequence Data: We used curriculum learning to train our SN-13B-8k-Instruct. We first trained the model on 300B tokens of short sequence data of length 2K. We then further trained the model for an additional 250B tokens on samples of 8K sequence length. During this phase of training, we curated a dataset that has a large proportion of long sequence articles with 30% of our articles consisting of greater than 6000 words.
Document Attention with Packed Data: To accelerate training, we packed all our text data into sequences up to the maximum sequence length. To ensure that the attention heads do not attend to different articles that were part of the same sequence, we implemented Document Attention masking, which is similar to the approach introduced in the OPT-IML paper.
INSTRUCTION TUNING
Enhancing long sequence tasks: We applied instruction tuning on a variety of tasks derived from datasets such as FLANv2, P3, NLI, etc. To optimize the model for long sequence tasks, we curated samples and tasks that specifically need long sequence context to provide a meaningful completion. To establish which long sequence tasks to include, we subsampled the tasks and trained the model on smaller versions of these datasets. This allowed us to analyze the results both quantitatively and qualitatively, and to determine which tasks provided benefits to long sequence understanding. We then created a specialized instruction-tuned dataset based on these tasks and combined it with our existing instruction tuned datasets.
Increasing the volume of long sequence task data using synthetic methods: To create additional long sequence data, multiple short articles were combined to teach our model to extract information across the resulting long sequence. We call this Instruction List Packing.
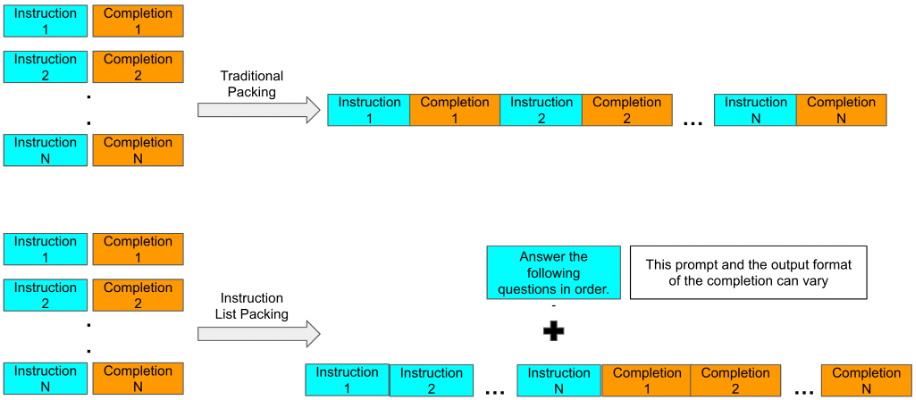
By changing the order of the instruction and the completion, we encourage the model to attend to the relevant portions of the text to generate a completion. Given that each completion requires attending to a different part of the prompt, by playing around with the initial prompts using instructions like “answer in reverse order”, we can encourage the model to learn to attend across longer lengths. Additionally, such samples can be created easily using simple python templates.
EVALUATION
Benchmark Results
We tested our model on tasks targeting an assortment of long sequence lengths, which were taken from Scrolls and ZeroScrolls. Both of these benchmarks measure the models’ ability to reason over long sequences of text. The Scrolls benchmark was used by Salesforce to evaluate their XGen model. The ZeroScrolls benchmark is a modification of Scrolls, and adds additional tasks. However, because ZeroScrolls only exposes a relatively small validation set, we also performed benchmarking on the Scrolls validation sets, which are much more comprehensive.
Quantitative Results
Our checkpoint shows better performance than existing open source long sequence checkpoints on selected tasks from the Scrolls benchmark. To test long sequence summarization and question answering, we benchmarked the models on the following tasks: Government Report, Quality, QMSum, and SummScreenFD.
- Government Report: A collection of summarized reports addressing various national policy issues
- SummScreenFD: A TV show summarization dataset
- QMSum: A query-based meeting transcript summarization dataset
- QuALITY: A multiple-choice question answering over articles and stories dataset
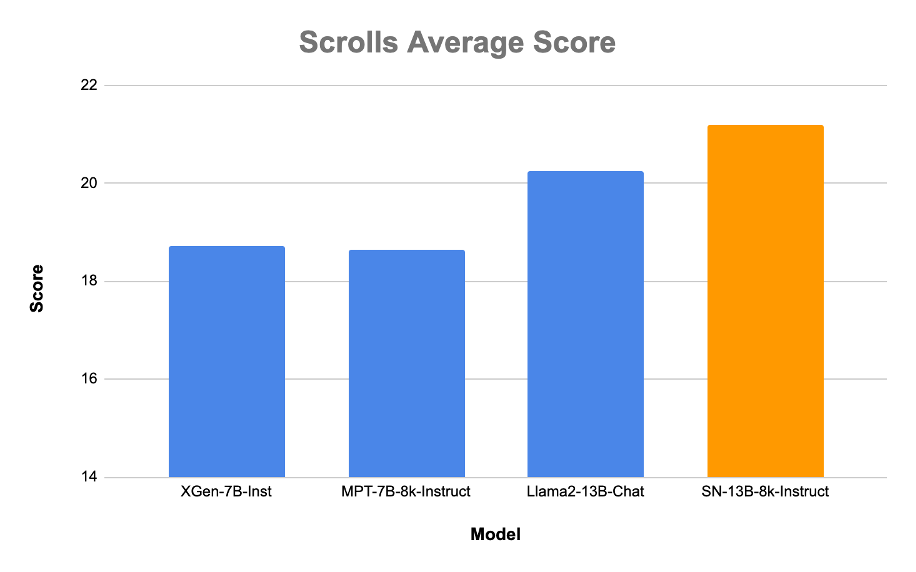
Average score on 4 benchmarks from Scrolls: Government Report, Quality, QMSum, and SummScreenFD. Scores were computed based on the validation set.
The SN-13B-8k-Instruct model also performs well on the validation set of the ZeroScrolls benchmark. Since the test set of ZeroScrolls is not publicly available, we benchmarked the validation set. Overall, the SN-13B-8k-Instruct outperforms XGen, MPT and LLAMA2-Chat on these benchmarks by as much as 10 points.
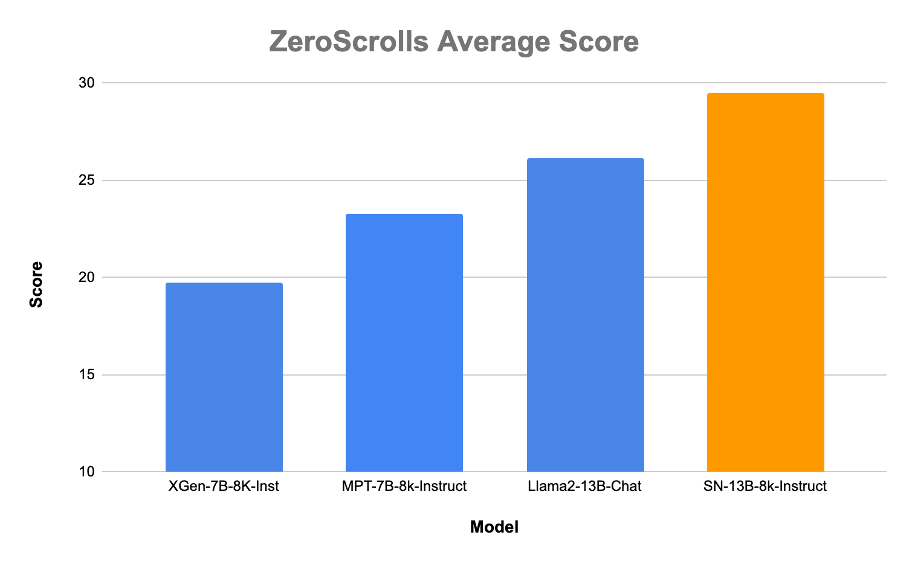
Average score on all 10 benchmarks from ZeroScrolls: Government Report, SummScreenFD, QMSum, SQuality, Quality, NarrativeQA, Qasper, MuSiQue, SpaceDigest, and BookSumSort. Scores were computed on the validation sets.
CONCLUSION
This demonstrates that using the methodology discussed in this blogpost, one can train a long sequence model that delivers quantitative advantages for long sequence length tasks. We offer our methodology and the resulting model as a resource to the open source community to further advance long sequence capabilities, and to add a new competitive baseline for long sequence tasks.
Please feel free to join our sn-13b-8k-instruct channel on Discord to further discuss and chat with the team!
APPENDIX
Task Specific Breakdown of Results
Scrolls Breakdown:
|
Task |
Metric | XGen 7B 8K Inst | MPT 7B 8k Instruct | Llama2 13B Chat | SN 13B 8k Instruct |
| GovReport | Rouge Geometric Mean | 16.38 | 10.75 | 15.80 | 23.89 |
| Quality | Exact Match | 33.70 | 42.14 | 39.98 | 38.26 |
| QMSum | Rouge Geometric Mean | 13.37 | 9.05 | 14.00 | 11.01 |
| SummScreenFD | Rouge Geometric Mean | 11.39 | 12.59 | 11.25 | 11.60 |
ZeroScrolls Breakdown:
|
Task |
Metric | XGen 7B 8k Inst | MPT 7B 8k Instruct | Llama2 13B Chat | SN 13B 8k Instruct |
| GovReport | Rouge Geometric Mean | 18.30 | 17.23 | 18.57 | 23.28 |
| SummScreenFD | Rouge Geometric Mean | 11.52 | 13.39 | 11.79 | 10.79 |
| QMSum | Rouge Geometric Mean | 11.22 | 10.34 | 13.37 | 9.05 |
| SQuality |
Rouge Geometric Mean |
14.52 | 6.74 | 17.86 | 5.13 |
| Qasper | F1 | 9.35 | 39.91 | 14.85 | 37.47 |
| NarrativeQA | F1 | 21.93 | 24.42 | 10.28 | 36.50 |
| Quality | Accuracy | 38.10 | 33.33 | 66.67 | 47.62 |
| MuSiQue | F1 | 20.34 | 17.71 | 6.01 | 20.14 |
| SpaceDigest | Exponential Similarity | 35.32 | 44.82 | 53.96 |
57.39 |
| BookSumSort | Concordance Index | 16.92 | 27.75 | 47.76 |
47.76 |
Contamination Study
Contamination is an important issue when using benchmarks to measure generalization. We do a thorough investigation of dataset contamination. Based on this, we found evidence of partial contamination for some tasks in ZeroScrolls in our training corpus. This was contamination at a task level, but not at a sample level, i.e. the samples we benchmarked on were not part of the training set. In order to see whether the improved numbers we see when compared to other open source models can be attributed to the training methodology we discuss and not to partial contamination, we also measure ZeroScrolls average on tasks that we know are not contaminated in our dataset. The results on the subset of tasks does still indicate that our training recipe can help achieve better results on ZeroScrolls than other open source models. An important point to note is that we did not perform any contamination study for the open source models.
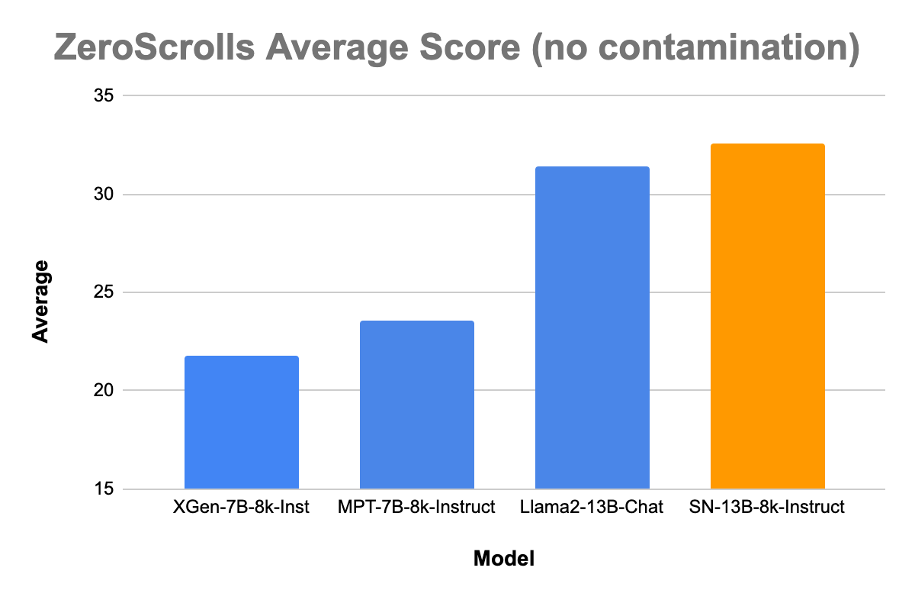
Average score on ZeroScrolls after removing tasks which were present in our training set (task level contamination). This was task level contamination, not sample contamination, so the actual samples we benchmarked on were not contaminated.
Performance on Short SS tasks
In addition to evaluating the models on long sequence tasks, we also performed evaluation on a variety of tasks from HELM.
| Task | XGen 7B 8k Inst | MPT 7B 8k Instruct | Llama2 13B Chat | SN 13B 8k Instruct |
| TruthfulQA | 25.00% | 16.30% | 36.10% | 22.00% |
| IMDB | 87.90% | 89.90% | 91.80% | 96.10% |
| BoolQ | 72.10% | 73.60% | 76.10% | 64.30% |
| NaturalQuestions (closed) | 24.10% | 20.0% | 33.20% | 23.30% |
| NarrativeQA | 47.6% | 68.2% | 21.9% | 72.1% |
| MSMARCO (regular) | 19.20% | 14.10% | 22.50% | 11.10% |
| MSMARCO (trek) | 36.50% | 32.80% | 40.70% | 27.20% |
| CNN-DM | 12.00% | 11.70% | 15.40% | 13.2% |
Reproducibility of Results
All results were collected using EleutherAI’s Eval Harness.
We directly used the Scrolls implementation in the Eval Harness framework to benchmark all models. The only modification we made was removing the newline stop token, allowing all models to generate until their end of text token. This is because the newline stop token would often result in empty or very short predictions if the models generated a newline at the beginning of their prediction.
We had to integrate the ZeroScrolls implementation into the Eval Harness framework since it had not been implemented yet. We directly used the ZeroScrolls prompts for all tasks except for MuSiQue, SpaceDigest, and BookSumSort. For MuSiQue we moved the instruction from the start of the example to the end, right before the Question. This was done to ensure the model attended to the part of the instruction which told the models to write ‘unanswerable’ if the question could not be answered based on the information in the paragraphs. For SpaceDigest and BookSumSort, the models often failed to generate outputs in the correct format. To incentivize the models to output currently formatted results, we appended a small example to each. These prompts were applied to all models, and we saw an improvement in model performance compared to using the original ZeroScrolls prompts directly. If for any model, we did not see an improvement, we report their model performance using the original ZeroScrolls prompts.
We evaluated models on QuALITY using both open ended generation as well as choosing the option with the highest normalized log probability. For each model, we reported whichever method yielded the higher accuracy.
When evaluating Llama2-chat, all prompts were truncated to length 4096, which is the maximum sequence size of Llama2. For all other models, the prompts were truncated to length 8192.
All results were collected using a max generation tokens of 256 as it is the default setting in the Eval Harness.
We have added more reproducibility information in our GitHub repository

