
 EN
EN
.jpg?width=1024&height=683&name=Out-of-thebox-computer-vision-scaled-1%20(1).jpg)
Given recent advances in computer vision, the popularity of convolution-free models has risen quickly, demonstrating state-of-the-art accuracy in various tasks, such as image classification, segmentation and generation.1 2 3 In light of these recent advances, vision transformers and multi-layer perceptrons (MLP) models can already achieve ~90% Top-1 accuracy on the standard benchmark ImageNet dataset. Such advances in accuracy challenge our previous belief in the handcrafted inductive bias in the popular convolutional neural networks and have triggered an interesting research direction for computer vision models where the model backbone is (mostly) convolution-free.
In this computer vision revolution, new variations and innovations in convolution-free model architectures erupt every week, continually elevating state-of-the-art accuracy across tasks and increasing computational cost. Training these convolution-free models can be computationally expensive. In certain cases, the number of FLOPS required to train a convolution-free vision model is estimated to be 5 to 10 times more than representative convolutional models.1 Because of this computational obstacle, exploring and leveraging the rapidly evolving convolution-free models becomes a game in which only a very limited number of players can participate.
At SambaNova, we are on a mission to democratize access to state-of-the-art deep learning models for enterprises—even without an army of ML engineers or a powerful in-house infrastructure. Towards this goal, we are quickly developing a series of vision convolution-free variations on our software and hardware stack. With these recent models, including several that were released in the past few weeks, we have achieved strong training performance, providing up to 4.6x speedup over flagship A100 GPUs from Nvidia.
To demonstrate the throughput of vision convolution-free variants from our agile bring-up process, we compare the throughput of A100 across four different popular recently released architectures: MLP-Mixers4, CVT5, CCT5, and gMLP.6 CVT and CCT mainly consist of transformers, whereas MLP-Mixer and gMLP replace attention modules with MLP modules variants. These vision convolution-free models also cover wide structural variations where the ordering of atomic layers, the number of layers, representation dimensionality, and pooling method are drastically different (as demonstrated in Table 1, and Figure 1).
| Model | Number of layers | Number of heads | Hidden dimension |
| gMlP6 | [30, 30, 30] | N/A | [128, 256, 512] |
| MlpMixer4 | [12, 24, 32] | N/A | [512,768, 1024] |
| CCT5 | [7,10, 12] | [4, 10, 12] | [256, 512, 768] |
| CVT5 | [7, 10, 12] | [4, 10, 12] | [256, 512, 768] |
Table 1: We follow the setup in the publications and measure throughput for each model in three different sizes: small, basic and large. Among them CCT and CVT have an input size of 32×32 and the others have 224×224 as input.
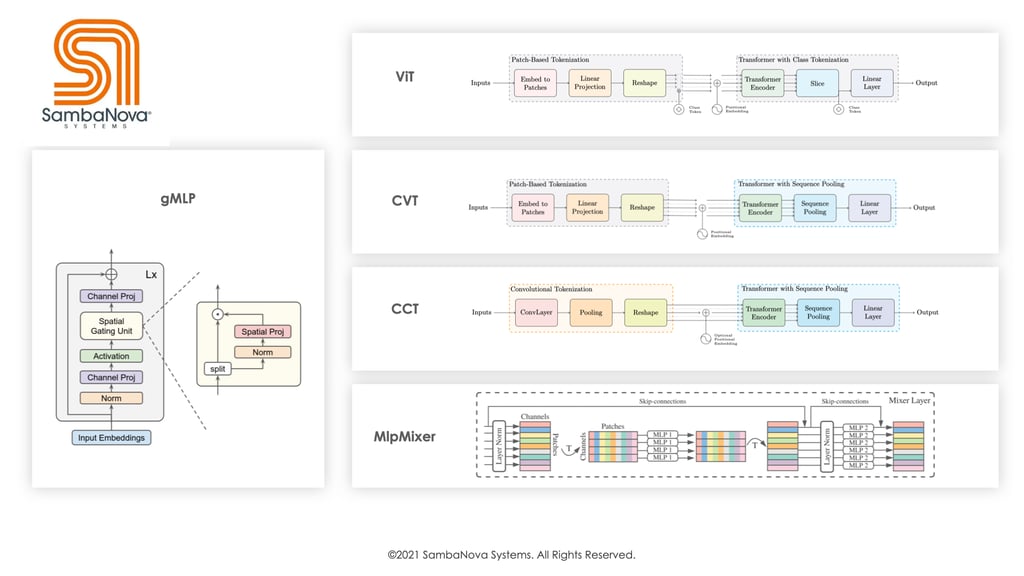
Figure 1: These models can vary significantly from one to another in terms of basic building blocks and overall architecture. For instance, MLP-Mixer and gMLP only have linear layers while CVT and CCT are based on self-attention units. Nevertheless, we are able to bring up all varieties of models swiftly and efficiently.
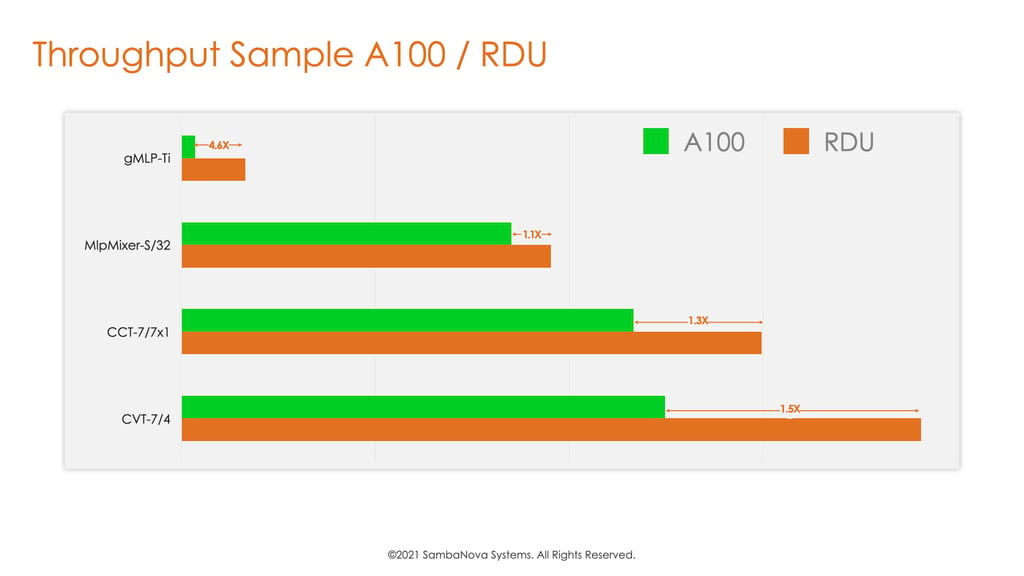
Figure 2: Here we visualize our throughput on various models against A100. On CVT and gMLP, we run significantly faster than A100, while on CCT, we are on par.
Across these convolution-free variations, as we can observe from Figure 2, RDU brings 1.1X to 4.6X throughput advantages across the board over AWS A100 out-of-box throughput using PyTorch model implementations. Noticeably among these convolution-free variations, gMLP is a new architecture released one week ago. Our agilent bringup of gMLP can demonstrate up to 4.6X speedup compared to PyTorch out-of-the-box throughput on A100 GPUs. These observations demonstrate the ability of our stack to bring up new trending vision convolution-free models in an agile fashion and show the system throughput advantage of our data flow architecture on these trending model architectures.
At SambaNova, we are excited to provide business and research institutions with the capabilities required to leverage quickly evolving model architectures. The ability to efficiently run these new models out of the box with our SambaFlow software stack reduces development time, while our DataScale systems simultaneously remove compute obstacles from your path and will empower your organization to achieve scientific and technological breakthroughs.
To learn how our full software and hardware stack can accelerate your machine learning deployments and keep you at the forefront of the technology wave, visit us at www.sambanova.ai.

