
 EN
EN

Achieving state-of-the-art accuracy using SambaNova Suite
In this blogpost, we show how one can use the SambaNova Suite to develop a Wav2vec [1] model that is highly optimized towards a specific domain or language. Our models lead to up to 25% lower absolute word error rate (WER) on conversational speech, and up to 10% lower on Hungarian narrative speech, when compared against leading cloud service provider’s speech-to-text transcription offerings, as well as the latest OpenAI Whisper APIa. We achieve this by leveraging advanced ML techniques from the open-source community like self-supervised pre-training [1], self-training [2] and advanced data curation pipelines. These ML capabilities and the associated models are available to our customers through simple low-code APIs from SambaNova Suite, with full governance on their data and their adapted model.
For many important enterprise use cases, voice interfaces serve as the medium through which a user interacts with large language model (LLM) technology. This can be for scenarios like call centers, virtual assistants, and audio and video conferences, etc. Given that these voice interfaces feed into a LLM model, a high-accuracy automatic speech recognition (ASR) system is a critical element towards downstream LLM task quality. However, it is challenging for an enterprise to develop and deploy a robust ASR system which is optimized for a specific language or customized to the domain (conversational, single-channel, call center, etc.) that a workflow focuses on.
The ML research community has stepped in to help alleviate this issue by open-sourcing models which are trained on open-source data in the generic domain. Ideally, this should enable any enterprise customer to get the benefits of these models out of the box. However, through our customer interactions, we identified two key challenges for enterprise customers’ production success on top of these open source models.
- First, to best serve their line of business, the models need adaptation on their domain data with enhanced accuracy and capability.
- Second, an enterprise-grade platform is required to enable quick experimentation and deployment of the state-of-the-art (SOTA) models.
The flexibility of the SambaNova platform, allows for rapid and quick adoption of these open source models while simultaneously providing the customization capabilities needed to adapt them to specific languages and domains. All of this can happen behind the customer firewall with full data and model governance. Many existing leading vendors do not have comparable capability.
Adapting open source ASR models to your domain
SambaNova Suite allows customers to adapt open source models to new languages and use cases, allowing them to reach a higher accuracy level compared to other cloud service providersb. To demonstrate the value that one can get from our platform, we adapt two open-source models, to the following languages and scenarios/domains:
- Two scenarios/domains – Narrative speech [3], and conversational phone calls [4, 5].
- Three languages – English, Japanese, and Hungarian.
We will first present the ASR adaptation pipeline in SambaNova Suite, followed by discussing the results produced by this adaptation pipeline. We then show that one can use our pipeline to attain strong adaptation accuracy with minimal audio labeling; this capability is critical for enabling enterprise customers to leverage their large volume of unlabeled in-house audio data without massive human labeling efforts.
Adaptation Pipeline
To seed our adaptation pipeline, we build on top of recent open source ASR models. Specifically, we adapt the well-known English-only robust-wav2vec model [6] for transcribing audio in English. For other languages, we adapt from XLSR-2b [7] which provides the largest and the most powerful multilingual pre-trained Wav2Vec backbone that can quickly adapt to each language individually, a capability that is not provided by most other vendors.
Once the right seeding checkpoint is identified, one needs to identify the data that represents the domain or language that we need to adapt this checkpoint to. For this blogpost, we use a heuristic based approach to filter high quality audios from large video repositories. The filtered audio runs through an automated pipeline to reformat, segment, label the data, and finally prepare them for model training.
Results
The results of this process of starting from an open source checkpoint and adapting to domain data can be found in Figure 1.
- First, we observe that by leveraging SambaNova Suite, we can tune on in-domain audio data, in a targeted language, achieving SOTA ASR transcript word error rate (WER) which is significantly lower than existing vendors. Specifically, in the phone call conversation domain, we observe that we can achieve up to 20% lower WER compared to results from the latest OpenAI Whisper API. Similarly, in the narrative speech setting, we can achieve 2% and 10% lower WER than the Whisper AI for Japanese and Hungarian respectively.
- In addition, we notice that the Hungarian language is not currently supported by the speech-to-text services provided by AWS. This highlights the gap that exists between the advanced capabilities existing in the open source community and conventional inference only API vendors, further cementing the need for a platform that can quickly adopt and deploy the rapidly evolving trends in ML open source movement.
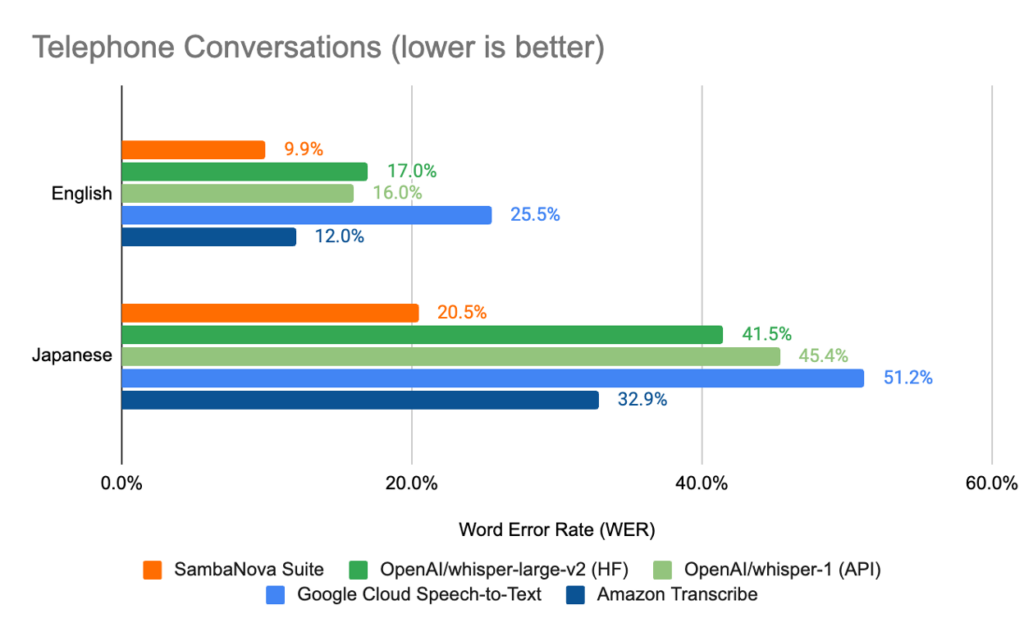
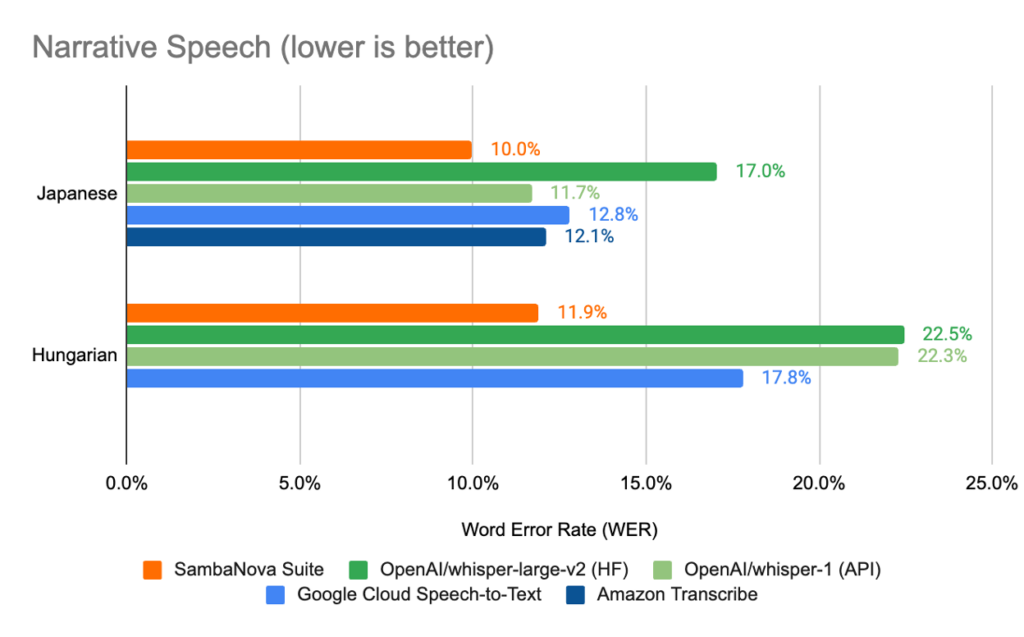 Figure 1: Word Error Rate (WER) comparison between SambaNova Suite and other alternative solutions on telephone conversations and narrative speech. Hungarian is not supported by AWS.
Figure 1: Word Error Rate (WER) comparison between SambaNova Suite and other alternative solutions on telephone conversations and narrative speech. Hungarian is not supported by AWS.
Adaptation with minimal human labeling
In enterprise settings such as call center use cases, there is a large volume of audio data available while only a minimal subset of the data is labeled with human transcription. Both from the research literature [7] and our in-house practice, we have seen that one can fine-tune the models with a limited amount of audio transcript labeling, and then these fine-tuned models can be iteratively improved using the pseudo labels generated by the model. Specifically in Figure 2, we can observe that for the Librilight dataset, one can leverage 60k hours of audios with only 10 hours of transcription labels. Surprisingly, this 10 hours of labeling induces only <2% WER gap compared to tuning with 100X more labels.
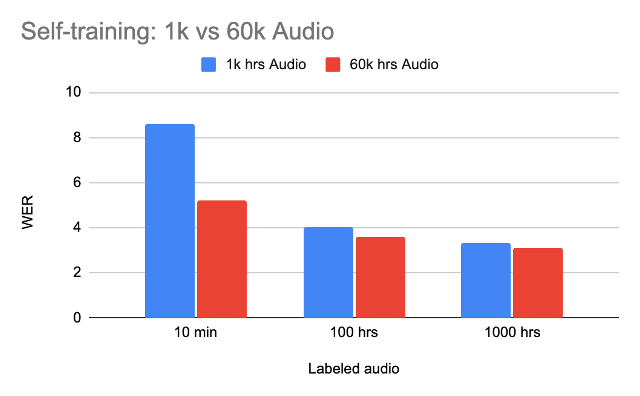
Figure 2
Conclusion
Having a good ASR system is key to unlocking downstream NLP capabilities in many enterprise scenarios. We are excited to enable our customer with the SambaNova suite to release the power of customers’ in-house audio data for the best in-domain accuracy.
Acknowledgement
We would like to express our deep appreciation to the work done by the following research groups. Their contributions to the advancement of ASR have not only been invaluable to the open source community, but also have inspired our approach leading to the results we are demonstrating in this blog post.
- Basevski et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
- Xu et al. Self-training and Pre-training are Complementary for Speech Recognition
- Hsu et al. Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
- Babu et al. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
References
[1] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (https://arxiv.org/abs/2006.11477)
[2] Self-training and Pre-training are Complementary for Speech Recognition (https://arxiv.org/abs/2010.11430)
[3] Common Voice, version 11.0 (https://commonvoice.mozilla.org)
[4] 2000 HUB5 English Evaluation Speech (https://catalog.ldc.upenn.edu/LDC2002S09)
[5] CALLHOME Japanese Speech (https://catalog.ldc.upenn.edu/LDC96S37)
[6] Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training (https://arxiv.org/abs/2104.01027)
[7] XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale (https://arxiv.org/abs/2111.09296)
[8] Librispeech dataset (https://www.openslr.org/12)
[9] Libri-Light dataset (https://arxiv.org/abs/1912.07875)
Footnotes
[a] We benchmarked all the competitors on Mar 6th, 2023.
[b] Amazon Transcribe, Google Cloud Speech-to-Text, and OpenAI Whisper API benchmark procedure disclosure
1. We used the Amazon Transcribe API, Google Cloud Speech-to-Text API, and OpenAI Whisper API to transcribe the following datasets for the four benchmarked scenarios
-
- Telephone conversation (English): 2000 HUB5 English Evaluation Speech
- Telephone conversations (Japanese): test set from CALLHOME Japanese Speech
- Narrative speech (Japanese): test set for Japanese from Common voice, v11.0
- Narrative speech (Hungarian): test set for Hungarian from Common voice, v 11.0
2. Calculate word error rate
- WER is being calculated on the output transcript without casing, punctuations, and numerical character substitutions
- For the telephone conversations (English) benchmark, Kaldi was applied to 2000 HUB4 English Evaluation Speech dataset to compute the WER
- For the remaining 3 benchmarks, WER was calculated between the transcribed text the API output and the ground truth text from the dataset based on edit distance
- Calculate and report the average WER across all measured samples

