
 EN
EN
A Collaboration between SambaNova Systems and Argonne National Laboratory
Using the capabilities of the SambaNova DataScale® system, researchers at the U.S. Department of Energy’s Argonne National Laboratory and SambaNova partnered on a collaboration to advance state-of-the-art performance of Graph Neural Network (GNN) kernels.
GNNs, which learn from graph representations of non-euclidean data, are rapidly rising in popularity, and are used in several computationally demanding scientific applications. However, GNNs have been known to suffer from hard memory and computational bottlenecks on traditional hardware platforms due in part to their reliance on non-regular data structures.
In this collaborative research, we demonstrate that the dataflow architecture of the SambaNova Reconfigurable Dataflow UnitTM (RDU) plus the significant on-chip memory can provide better performance on GNNs. Additionally, as part of this collaboration, a novel performance evaluation methodology was used to demonstrate significant inference performance speed up for certain operations related to state-of-the-art GNNs on SambaNova’s DataScale system.
The results show competitive performance for sparse operations related to GNNs without any explicit optimization, and show significant inference performance speed up for these operations. More specifically, the DataScale platform provides 2-3X performance compared to a leading GPU chip competitor on index_select_reduce, a key building operation of the sparse operations such as sparse-dense matrix multiplication.
AUTOMATED KERNEL FUSION ENABLED BY SAMBANOVA’S DATAFLOW ARCHITECTURE
GPUs and other conventional AI accelerators run ML applications kernel-by-kernel which requires frequent on- and off-chip data transfer. However, the SambaNova RDU provides a flexible, dataflow execution model that pipelines operations, enables programmable data access patterns, and minimizes excess data movement found in fixed, core-based, instruction set architectures employed by GPUs.
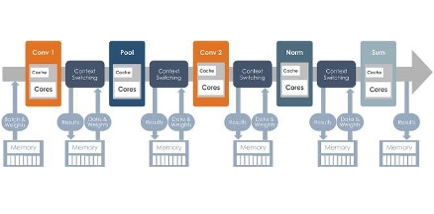
As depicted in Figure 1a, the kernel-by-kernel execution on a GPU executes one operation at a time and materializes the entire intermediate data off-chip, which requires high off-chip bandwidth for performance. In contrast, dataflow execution on an RDU (Figure 1a) enables high computation resource utilization and achieves the effect of kernel fusion that minimizes memory transfer costs, and removes the need to create custom one-off fused kernels which requires a specialized team of engineers.
Machine learning dataflow graphs are spatially compiled to the RDU. In this spatial mapping, communication between the graph nodes stays on chip and is efficiently handled by the on-chip interconnect compared to traditional architectures. The impact is a dramatic reduction in off-chip bandwidth compared to kernel-by-kernel execution.
(a) Kernel-by-kernel execution for GPUs
(b) Dataflow execution for RDU
Figure 1: Dataflow/architecture comparison of GPU and SambaNova RDU
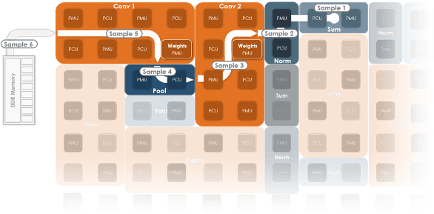
Additionally, the compiler for DataScale, SambaFlow, captures the ML application as a compute graph with parallel patterns and explicit memories, and systematically lowers the graph to a logical dataflow pipeline that exploits data, task, and hierarchical pipeline parallelism. Figure 1(b) shows dataflow execution on an RDU that concurrently executes multiple kernels of the same GNN model as a dataflow pipeline. Intermediate results are produced and consumed entirely on-chip, which lowers off-chip bandwidth requirements. This dataflow architecture has the potential to greatly accelerate development of GNN foundation models.
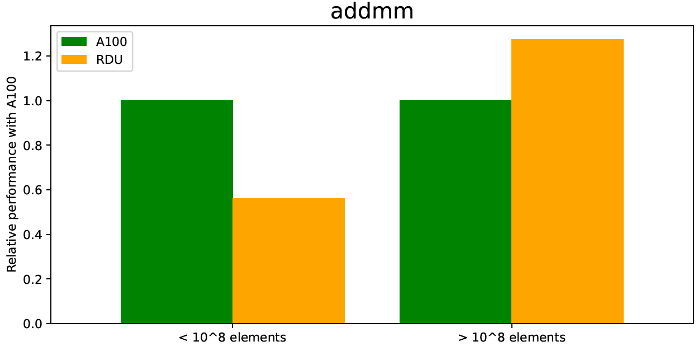
(a) AddMM
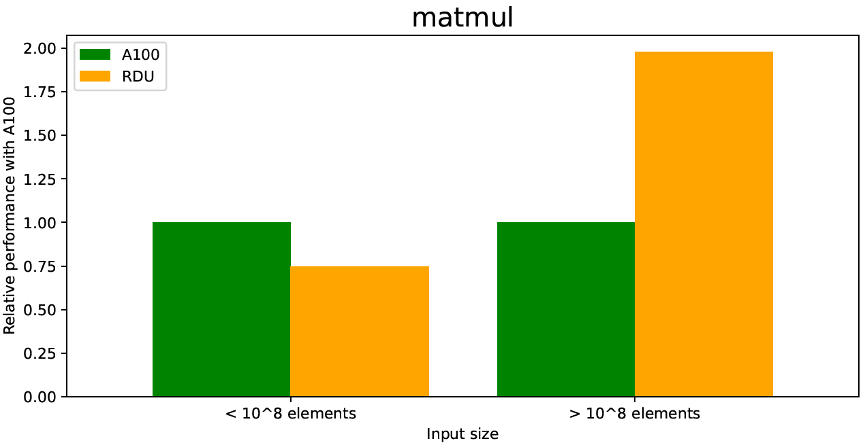
(b) MatMul
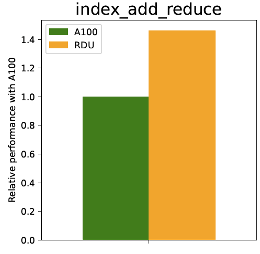
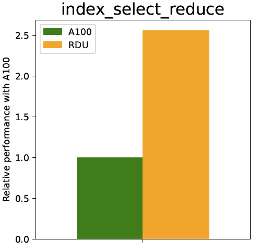
c) Index_add_reduce, and Index_select_reduce
Figure 2: RDU Performance comparison with A100 of various GNN operations
As depicted in Figure 2a, the RDU shows better performance on basic GNN arithmetic operations compared to an A100. For example, the matmul shows comparatively better performance, especially for larger input sizes (with similar FLOPS). This is mainly due to the sufficient on-chip memory and good tiling support of the SambaFlow compiler. On the other hand, as depicted in Figure 2b, the RDU provides a 2-3x performance boost compared to A100 on index_select_reduce. This is due to the fact that the RDU on-chip memory bandwidth (150TB/s) is significantly faster than the A100’s off-chip high bandwidth memory (HBM) bandwidth (2TB/s). The performance of the RDU on index_add_reduce is similar, with a reported 30-50% performance boost, depending on the input size.
NOVEL PROFILING FRAMEWORK
One of the main challenges with deep neural networks in production is meeting the low latency requirements required by downstream workflows. Many domains require low-latency inference of user data, often at very small batch sizes. However, as the number of parameters in state-of-the-art architectures continue to increase, inference performance, in terms of runtime, can become progressively problematic.
As mentioned previously, emerging AI accelerators, such as the RDU, provide specific optimizations for runtime performance of deep learning models such as GNNs. Performance can be even further improved with additional optimization that can require substantial engineering effort. Thus, a method for assessing the viability of specific applications can help hardware developers assess the viability of development of specific models. Such a method can also help application developers assess the viability and promise of AI accelerators for different use cases.
In this collaboration, Argonne addresses the issues described above by introducing the microbenchmark framework, which facilitates comprehensive and equitable performance comparisons of portions of end-to-end deep learning architectures on emerging hardware platforms. This framework can also be used to assess performance bottlenecks and inform future optimizations at the hardware, system software, and algorithm level.
CONCLUSION
Due in part to systems and hardware features (i.e. dataflow architecture and smart compiler support) that result in automatic kernel fusion and memory optimization, RDU platforms present an exciting opportunity to accelerate the inference of GNNs compared to existing, well established systems such as A100 GPUs.
These capabilities present exciting potential for the development of GNN foundation models. As part of the continuing collaboration, Argonne and SambaNova are developing pre-trained GNN foundation models that are deployed at scale to serve downstream tasks with better performance and accuracy.
ACKNOWLEDGEMENTS
This research used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357
