AI Inference Is Fueling a Critical Data Center Power Crisis
Global businesses and investors are racing to harness AI’s capabilities, but a power crisis now threatens to derail the era’s biggest disruption. In 2023, Microsoft and Google alone burned through 48 TWh of electricity — a figure exceeding the annual power usage of 100 countries — with most of that energy dedicated to training AI models. Today, however, it’s AI inference and the deployment of those models at scale that promises to drive an even more explosive spike in energy demand across data centers. To meet the rising demand for AI inference with the power constraints of today, we need a better architecture that is more energy efficient to tap into power constrained data centers.
Data Center Growth and Investment Risk
According to Deloitte, the power demand for AI in data centers is predicted to grow from 4 GW in 2024 to 123 GW by 2035, a 31x increase! This is largely fueled by the requirements of next-generation GPUs, such as NVIDIA’s Blackwell NVL72, which require such vast amounts of energy — up to 120kW per rack, with exotic liquid cooling. Most existing data centers simply cannot host these systems without multimillion-dollar overhauls. Even more challenging is the next generation of NVIDIA GPUs, the Vera Rubin family, which has power requirements of up to 600 kW.
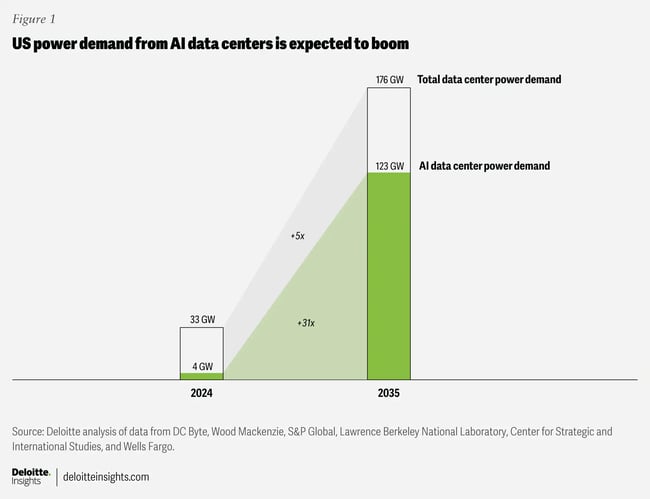
Building new data centers typically takes 18-24 months, but that is not the only challenge. According to another report from Deloitte, “Most power capacity development can take longer than data center build-outs, which can be completed in a year or two. Gas power plant projects that have not already contracted equipment, for example, are not expected to become available until the 2030s.” So even if new data centers are built, there is simply not enough energy available to meet the demand.
A different solution is needed to power AI inference.
SambaManaged: The most advanced, energy-efficient, and compliant AI inference platforms in the world
The ability to quickly deliver energy-efficient AI inference is why the SambaManaged platform has been adopted by multiple partners to serve the UK, Australian, and German markets. SambaManaged delivers a complete AI inference platform that is energy efficient and can run on existing power. Its low power requirement means that it is air cooled, which obviates the need for exotic liquid cooling systems. This enables each of these inference services to leverage their existing infrastructure without overspending on a complex data center build out. Finally, it is secure to meet the most stringent compliance requirements. Deployable in as little as 90 days, SambaManaged provides a complete sovereign AI inference cloud.
GPUs for Training, RDUs for Energy-Efficient Inference
GPUs are great for AI model training, which is the process by which AI models are presented with information, or “taught,” about the subjects on which they are to operate. AI inference, which is the process of using a trained model to answer questions or perform a task, presents a different computational challenge. AI model training is a data processing challenge, which is why GPUs have proliferated as the technology of choice for AI workloads. AI inference however, is a data flow challenge, and is better served by an alternative architecture.
Purpose-Built for Fast Inference with High Efficiency
The SambaNova SN40L Reconfigurable Dataflow Unit (RDU) uses an innovative dataflow architecture and three-tiered memory design. The dataflow architecture uses operator fusion to eliminate many of the redundant calls to memory that occur with GPUs. By dramatically reducing the number of kernel calls, the RDU can perform the same function faster and with less energy.

Comparing RDUs vs. GPUs Energy Efficiency
To provide a real-world comparison for power-constrained data centers, we will compare the NVIDIA H200 GPU, one of the most common GPUs in use in today's data centers that works with existing infrastructure, and the SambaNova SN40L Reconfigurable Dataflow Unit (RDU), a next-generation processor, purpose-built for AI inference. In our comparison, we will use two H200 systems. Each H200 has 8 GPUs for a total of 16. The SambaNova system has 16 RDUs, making this a fair comparison. While NVIDIA does have later generations like Blackwell and the upcoming Rubin, neither GPU works well in power-constrained environments.
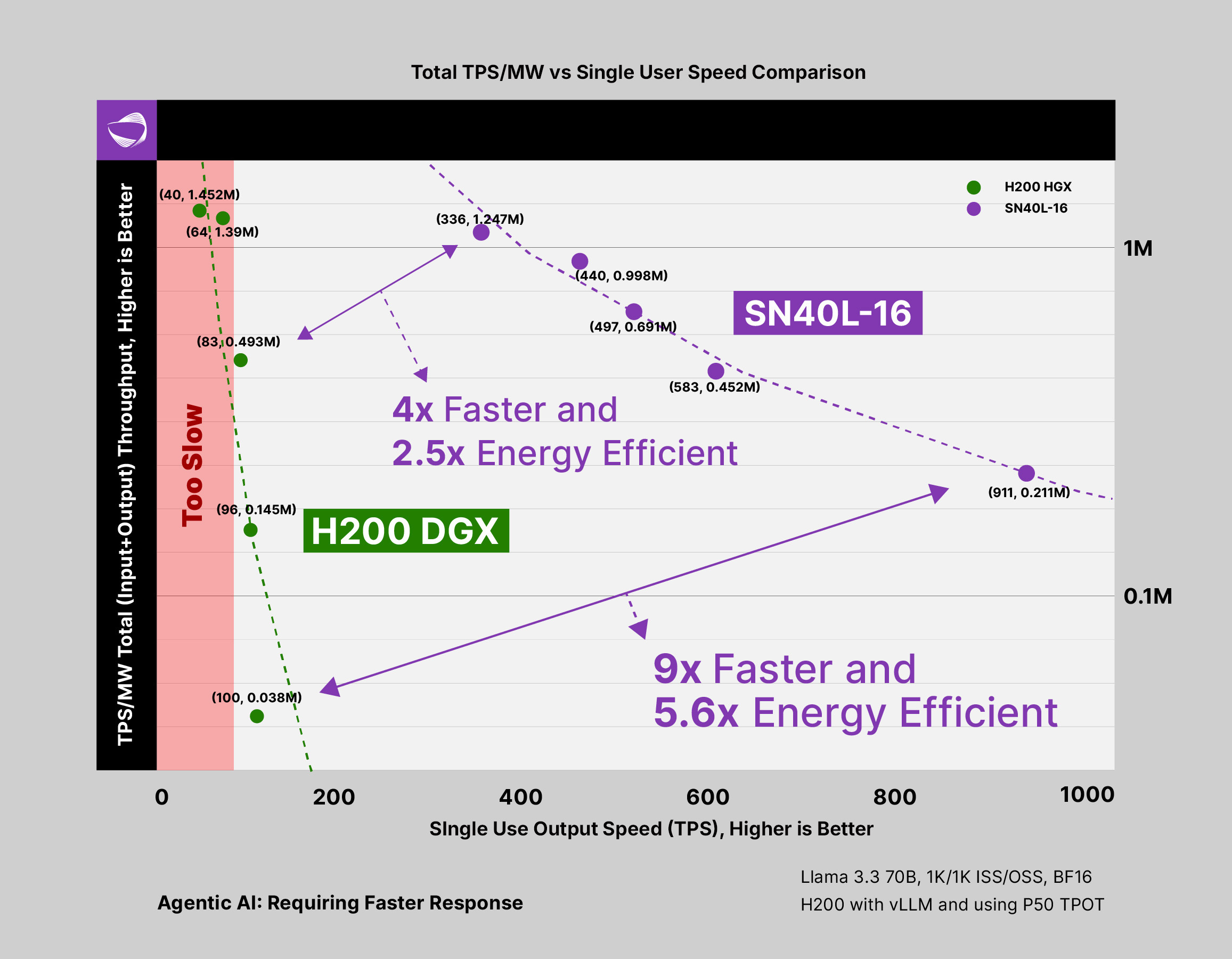
In the above diagram we can see that the SambaNova SN40L delivers significantly faster performance and better power efficiency than the NVIDIA H200 DGX. In this case, testing was done with the Meta Llama 3.3 70B model and using a range of batch sizes. On this chart the X axis is tokens-per-second (TPS) and the Y axis is TPS per megawatt. For both the H200 and the SambaNova SN40L, the higher the batch size, then the lower the single user output speed.
In all cases, SambaNova delivers both superior performance and higher energy efficiency. For low batch sizes, the SambaNova system delivered 9x greater performance while being 5.6x more energy efficient. Even with a higher batch size, putting the SN40L at a disadvantage, the SN40L is 4x faster and 2.5x more energy efficient than the H200.
It is not limited to one model. RDUs deliver superior performance to H200s across a range of models, as shown in the chart below.

Conclusion
The next wave of AI adoption will be bottlenecked by power and infrastructure constraints. SambaNova is disrupting the GPU-dominated landscape, with solutions positioned to deliver superior performance and lower power consumption.