

Speed
RDUs are the only solution that run the largest AI models with blazing-fast inference speeds.
Learn more →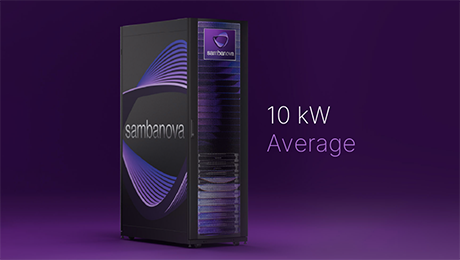
Energy
RDUs deliver the highest tokens per kilowatt-hour, which is ideal for existing air-cooled data centers of all sizes.
Learn more →
Agentic Caching
Faster inference requires agents to cache models and data on hardware. The three-tier architecture allows multiple models to run while switching between them.
Learn more →