Over the last year, SambaNova has been leading ahead on many of AI’s most recent challenges: energy, agents, and larger models to name a few.
How did we know these would become issues the AI industry faced? Because at its core, AI inference is a data and memory movement challenge. When you don’t solve this data movement problem efficiently, these industry challenges are unavoidable.
This challenge was a key driver among the founding principles of SambaNova nearly 10 years ago. The goal was to create an alternative hardware architecture for AI, which resulted in the development of the revolutionary Reconfigurable Dataflow Unit (RDU).
Today, thanks to the hard work of our amazing team, we are excited to announce our fifth-generation chip, the SN50, and SambaRack SN50 system. These technologies are both purpose-built to solve the challenge of agentic inference unlike any other platform.
What Is Agentic Inference?
Let’s start by first defining what is agentic AI and what is agentic inference? OpenClaw is the most recent example that has taken the developer world by storm. This open-source AI agent is capable of breaking a problem down into sub-tasks and completing those sub-tasks by connecting directly into our apps and tools using natural language.
Even today, when you use ChatGPT or any large language model (LLM) interface, OpenClaw creates a simplified version of this agentic loop to solve a user’s requests. The issue is that it requires a chain of individual calls to an LLM. For many use cases like coding, this introduces unacceptable latency with typical GPU configurations that impairs the developer experience.
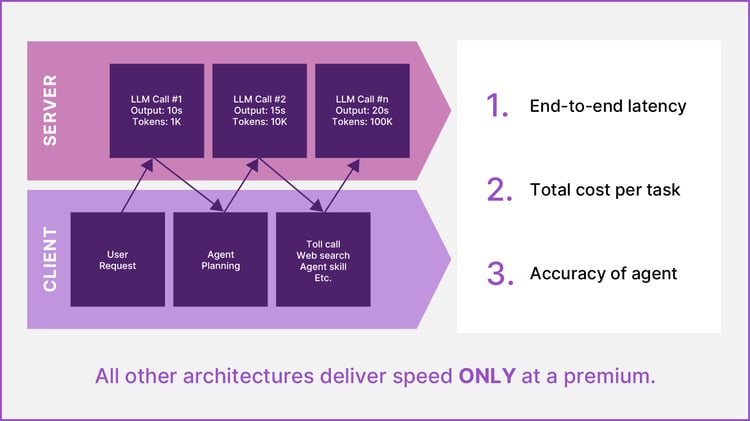
Latency can be improved only slightly on GPUs. Anthropic recently introduced a fast mode for Opus 4.6, where they were able to 2.5X the speed, but this comes with a steep penalty of 6X the cost.
Further, this “fast mode” barely meets the minimum speed demands for agentic inference and for these AI agents to deliver near-real time answers. The challenge with all other hardware solutions today is that delivering this speed becomes prohibitively expensive or unscalable for inference service providers.
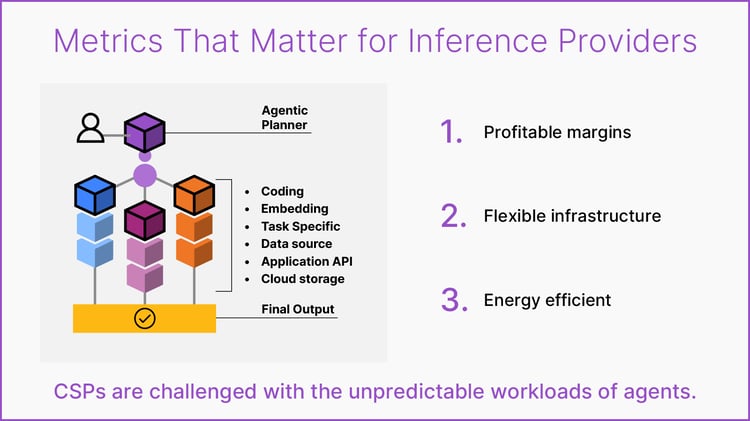
Tokenonomics that Make Sense for Agents
The SN50 RDU delivers an unmatched blend of ultra‑low latency, high throughput, and power‑efficient performance for AI inference workloads, fundamentally reshaping the economics of token generation.
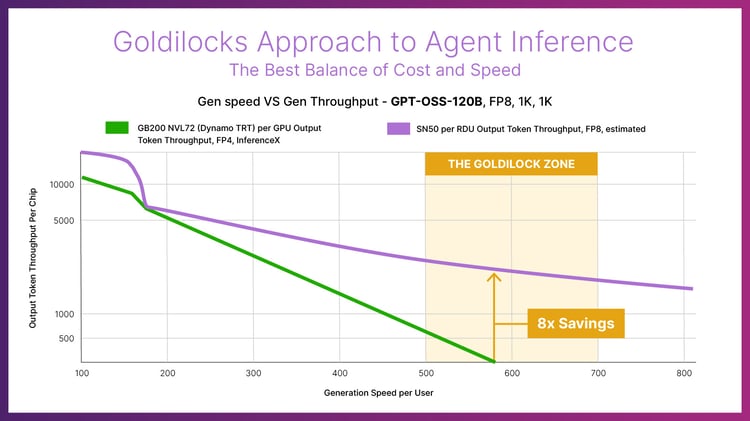
Compared to Blackwell B200 GPUs, the SN50 delivers 5X the maximum speed and over 3X the throughput for agentic inference as highlighted across an array of models, such as Meta’s Llama 3.3 70B, which is a widely used open-source model even several years since it was released.
.jpg?width=750&height=422&name=Chart%20-%20Gen%20speed%20VS%20Gen%20Throughput%20-%20Llama%203.3%2070B%20-%20v3%20(1).jpg)
This impressive performance is delivered while averaging just 20 kW of power in a SambaRack, which allows the rack to operate in existing air-cooled data centers. This combination of performance, efficiency, and scalability translates into a total‑cost‑of‑ownership (TCO) advantage that is unparalleled in the market for inference service providers running models like gpt-oss at 8x the savings of B200s GPUs.
Agentic Caching
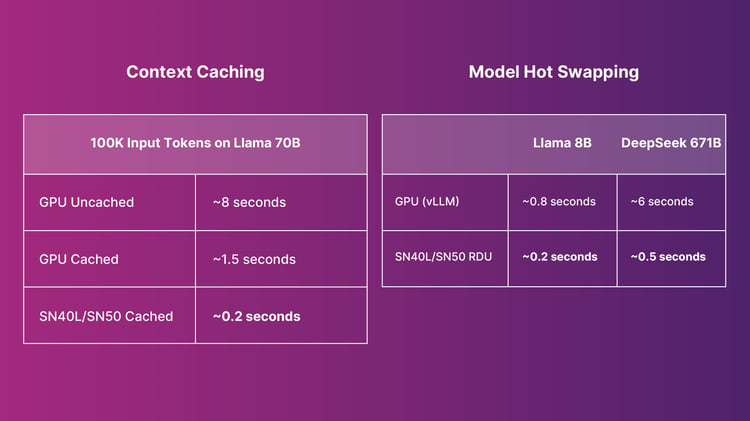
Just like the SN40L RDU, the SN50 RDU features a tiered memory architecture that combines large‑capacity memory, high‑bandwidth memory (HBM), and ultra‑fast SRAM. This hierarchy enables the chip to host the largest models while simultaneously running many models in parallel.
Models residing in HBM and SRAM can be hot swapped in milliseconds, a capability that is essential for agentic workloads switching frequently between multiple models.
Moreover, with our SN50, input tokens can be cached in memory, reducing pre-fill processing time and the Time to First Token (TTFT) for requests. In combination, our memory architecture becomes ideal for agents as an agentic cache that can process tasks even more efficiently.
Next Generation Scale Out
The SambaRack SN50 combines 16 SN50 chips together to deliver five times more compute per accelerator and four times more network bandwidth than the previous generation.
Interconnected SambaRacks can scale up to 256 accelerators over a multi‑terabyte‑per‑second interconnect, which cuts TTFT and supports larger batch sizes. As a result, models with higher throughput and responsiveness can be deployed.
Capable of supporting the largest models of today and tomorrow, the SN50 can run individual models up to 10 trillion parameters in size and context lengths of up to 10 million tokens.

Dataflow Architecture
At the heart of the SN50 is the Dataflow Architecture, which enables high performance and high efficiency.
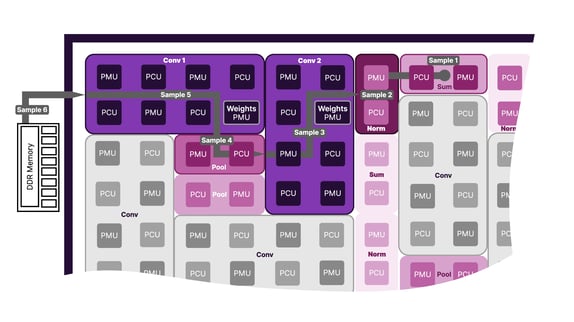
While GPUs are good at AI model training, a compute heavy function; AI inference is data movement and memory optimization challenge that requires a different architectural approach.
To perform AI inference GPUs must make multiple, redundant calls to off-chip memory. Each memory call adds latency to the process and consumes energy, which is why GPUs demand so much power.
Alternatively, RDUs map the graph of a given AI model to the most efficient path for moving data across the processor. This approach eliminates redundant calls to memory, which drastically reduces latency and power consumption.
The Future is Agentic and Needs Dataflow
As the industry adopts more and more agents, we will need a better full-stack architecture – from chips to models – to better serve these agents. The SN50 RDU is built for this future and will start shipping to customers in the second half of 2026. Excited to learn more about the SN50 RDU, the SambaRack SN50, and Dataflow? Connect with our team of experts!