
背景
リカレントニューラルネットワーク(RNN)は、製造分野では予知保全におけるLSTMモデル、医療分野ではCovid-19創薬におけるGRUベースのエンコーダとデコーダ、金融の時系列予測など、異なる産業で広く使用されています。RNNは基本的に時系列の予測問題で動作するように設計されています。RNNはフィードフォワードニューラルネットワークではなく、フィードバックニューラルネットワークであるため、学習が困難です。RNNは、信号が前方にも後方にも移動し、数値や値がネットワークにフィードバックされる、さまざまな「ループ」をネットワーク内に含むことがあります。
GPUでRNNを扱う課題:並列処理プロセッサ上での逐次計算
RNNモデルは逐次的であり、RNNでは多くの小さな演算が再帰的に起こるため、多くの小さな演算コアを持ち並列に計算を行うGPUアクセラレータには適していません。その結果、逐次計算ではGPUの計算能力を十分に活用することができません。もっとわかりやすく言うと
- GPUはカーネル単位で実行しますが、RNNは基本的に多くの小さなカーネルが再帰的にループする構造である。
- RNNの計算ではオフチップメモリアクセスとカーネルディスパッチのコストは無視できない。
そのため、RNNのような演算パターンではGPUの使用率が低く、効率が悪いため、特に推論や学習のパフォーマンスが低下する原因となります。
SambaNovaの再構成可能なデータフローアーキテクチャがRNNの性能を加速させる理由
SambaNovaの再構成可能なデータフローアーキテクチャ(Reconfigurable Dataflow ArchitectureTM)は、アルゴリズム、コンパイラ、システムアーキテクチャ、最先端シリコンを含むすべてのレイヤーでイノベーションを取り入れた、新しいコンピューティングアーキテクチャです。再構成可能なデータフローアーキテクチャでは演算ロジックを空間的にパイプライン化し、プログラマブルなデータアクセスによって、データ移動を最小限に抑える、柔軟なデータフロー実行モデルを提供します。再構成可能なデータフローアーキテクチャの中核はネイティブなデータフロー処理とプログラマブルなアクセラレーションを実現するために設計された次世代プロセッサ、SambaNova Reconfigurable Dataflow UnitTM(RDU)です。具体的には、大容量オンチップメモリとメタパイプライン実行を用いることで、RNNは以下のような恩恵を受けることができます。
- RNNモデルのグラフは、カーネル単位の実行モデルを用いずに、RDUにマッピングされる。
- カーネル単位の実行モデルでのホストからアクセラレータへのディスパッチのコストがないため、オフチップメモリアクセスのオーバーヘッドは削減される。.
SambaNovaのソフトウェア・ハードウェア統合スタックは、GRU、RNN、LSTM、その他のカスタム時系列モデルなど、あらゆるリカレントモデルにおいて、超高速オンライン推論とバッチ学習パフォーマンスを実現します。グラフ全体をより効率的にRDUにマッピングし、高い利用率と並列計算による最適化された性能を導入してすぐに実現出来ます。このように、SambaNovaはGPUに対して必然的な優位性を持っています。
RDUとGPUによるLSTMとGRUの性能比較
様々なLSTM/GRUモデル構成で実験した結果、オンライン推論性能で4倍、小規模LSTM学習性能で5倍、中・大規模GRU学習性能で2倍程度の高速化が確認されました。SambaNovaのRDUとNVIDIA A100の比較性能は表1の通りです。
表1.RDUとA100の性能比較

注
1) BS=24, input_size=[25, 64], hidden_size = [64, 64], sequence_len=50
2) BS=64, Input_size=[170, 512, 512], hidden_size=[512, 512, 512], seq_len=100
比較対象のGPU性能については、NVIDIA A100 40GBとA100 80GBの両方で公開されているバージョンのNVIDIA-dockerを使って、最高のパフォーマンスの数値を採用しています。
IoT製造業データセットによるモデル精度結果
我々は航空機エンジンメーカー用のNASA TurboFanデータセットを用いて、予知保全のアプリケーションをLSTMベースの時系列モデルで開発しました。モデルサイズが小さい場合は2層LSTM、モデルサイズが大きい場合は4層LSTMの2つのモデル構成を検討し、用途に応じて回帰層と分類層の両方を組み込んでいます。
- 小さいモデルのための2層LSTMの構成:BS=64, n_features=25, hidden_size=25, sequence_length=50
- 大きなモデルのための4層LSTMの構成:BS=64, n_features=25, hidden_size=64, sequence_length=50。
表2より、RDUは2層のLSTMモデルをA100の4.6倍の速度で学習できることがわかります。それだけでなく、より深い4層LSTMモデルの場合でも、RDUはA100が2層LSTMモデルを学習するのにかかる時間より4倍速く学習することができます。同じ時間でRDUはより優れた学習時間指標を達成することができ、稼働中の機械のより低い予測損失(図1)や機械故障時間のより高い予測精度(図2)を提供します。このように機械学習アプリケーションでは、最新の精度と高速な学習性能の両立が重要です。
表2.IoT時系列モデルの学習スループットと精度
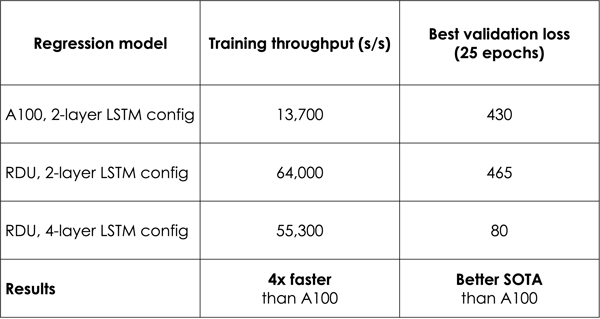
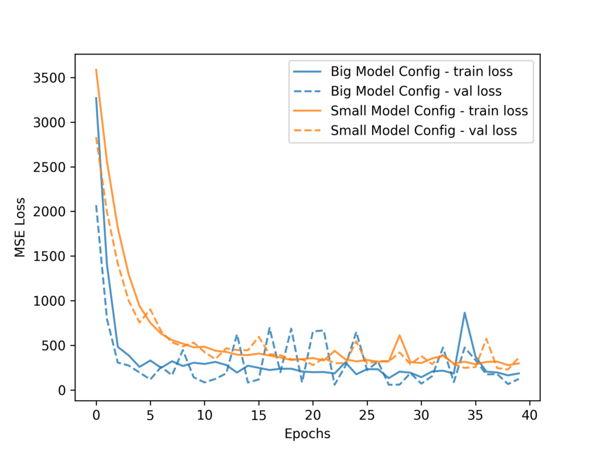
図1.回帰モデルの学習と検証曲線
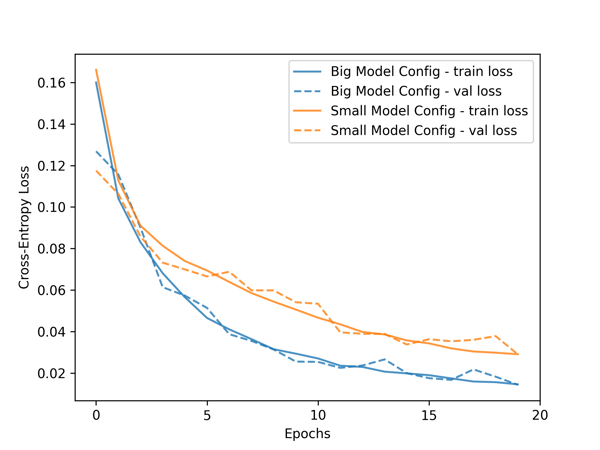
図2.分類モデルの学習・検証曲線
結論と総括
測定結果が示すように、SambaNovaのRDAの大容量オンチップメモリとメタパイプライン実行により、「並列プロセッサ上の逐次計算」の課題を克服し、LSTMとGRUの学習と推論の両方でGPUに対して大きな性能優位性を持つことになります。
これらの性能向上は、様々な業界における言語モデリング、テキスト生成、音声・画像認識、時系列予測、コールセンター分析、その他多くのアプリケーションやドメインで大きな影響を与える可能性があります。