
Background
Recurrent neural networks (RNNs) are widely used in different industries, such as time-series long short-term memory (LSTM) models in predictive machine maintenance for IoT manufacturing applications, gated recurrent unit (GRU)-based encoder and decoder in Covid-19 drug discovery for medical applications, financial time series prediction, and more. They are essentially designed to work with sequence prediction problems. RNNs are hard to train, as they are not feedforward neural networks, but feedback neural networks. They can have signals traveling both forward and back, and may contain various “loops” in the network where numbers or values are fed back into the network.
RNN Challenges on GPU: Sequential Model Computation On Parallel Chip Processing
Due to RNN models’ sequential nature and many small operations happening recurrently in RNNs, they are not well-suited for GPU accelerators which have many small cores performing computations in parallel. As a result, sequential computation can’t fully utilize GPUs computing power. To be more explicit,
- GPUs use kernel by kernel execution, while RNNs have essentially many small kernels coming in a recurrent loop fashion.
- The off-chip memory access and kernel dispatching costs are not negligible in such RNN cases.
Thus these operations cause low utilization and low efficiency on GPUs, which especially leads to slow inference and training performance.
How SambaNova’s Reconfigurable Dataflow Architecture accelerates RNN performance
SambaNova’s Reconfigurable Dataflow ArchitectureTM (RDA) is a new computing architecture technology that incorporates innovations at all layers including algorithms, compilers, system architecture and state-of-the-art silicon. The RDA provides a flexible, dataflow execution model that pipelines operations, enables programmable data access patterns and minimizes excess data movement. RDA includes the SambaNova Reconfigurable Dataflow UnitTM(RDU), a next-generation processor designed to provide native dataflow processing and programmable acceleration. Specifically, using large on-chip memory and meta-pipeline execution, RNNs can benefit from the following:
- The graph of RNN models is mapped on a chip without a kernel by kernel execution.
- The off-chip memory access overhead is reduced without the kernel by kernel cost to dispatch from host to accelerator.
SambaNova’s integrated software-hardware stack can work with any recurrent models, such as GRU, RNN, LSTM, or other custom time-series model, providing ultra-fast online inference and batch training performance. Out-of-the-box, we are able to map the entire graph more efficiently onto the RDU with high utilization and optimized performance using parallel computing. Thus SambaNova has a natural advantage over GPUs.
Comparing LSTM and GRU Performance across RDU and GPU
After experimenting with various LSTM/GRU model configuration settings, we observe 4x speedup for online inference performance, 5x speedup for small config LSTM training performance, and about 2x speedup for medium to large GRU training performance. Performance numbers comparing SambaNova’s RDU and Nvidia’s A100 are listed in Table 1.
Table 1. Performance Comparison between RDU and A100

Footnotes:
1) BS=24, input_size=[25, 64], hidden_size = [64, 64], sequence_len=50
2) BS=64, Input_size=[170, 512, 512], hidden_size=[512, 512, 512], seq_len=100
For GPU baselines, we are measuring the best performance numbers on Nvidia- docker and out-of-the-box using publicly available versions on both Nvidia A100 40GB and A100 80GB.
Model Accuracy Results Using the IoT Manufacturing Dataset
We have developed LSTM based time-series models in predictive machine maintenance applications using the NASA TurboFan dataset for an aircraft engine manufacturer. We consider two model configurations with 2-layer LSTM at small model size and 4-layer LSTM at big model size, and incorporate both regression and classification layers for different application purposes.
- 2-layer LSTM config with small model size: BS=64, n_features=25, hidden_size=25, sequence_length=50
- 4-layer LSTM config with big model size: BS=64, n_features=25, hidden_size=64, sequence_length=50
Table 2 shows the RDU can train the 2-layer LSTM model 4.6x faster than A100. Not only that, for a deeper 4-layer LSTM model, RDU can train it 4x faster than the time A100 takes to train the shallower 2-layer LSTM model. In the same amount of time, RDU can achieve better time-to-train metric, by delivering much lower predictive loss of machine in-operation features (Figure 1) and higher prediction accuracy of machine broken time (Figure 2). Having both state-of-the-art accuracy with faster training performance is critical for machine learning applications.
Table 2. IoT Time-series Model Training Throughput and Accuracy
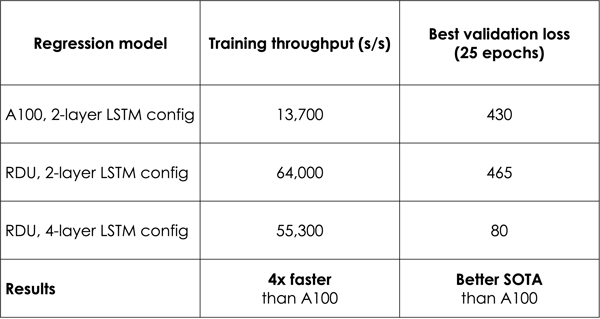
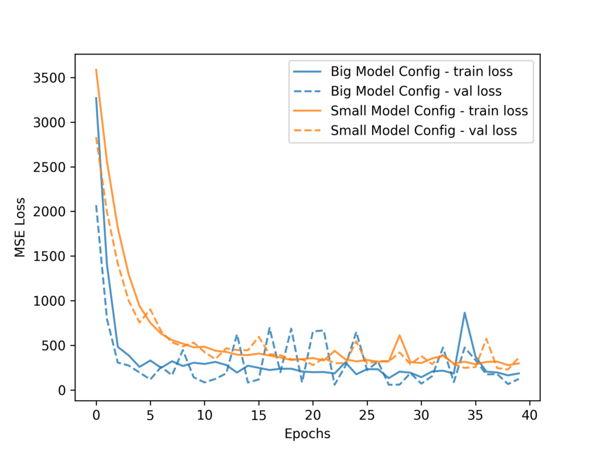
Figure 1. Regression Model Train & Validation Loss Curves
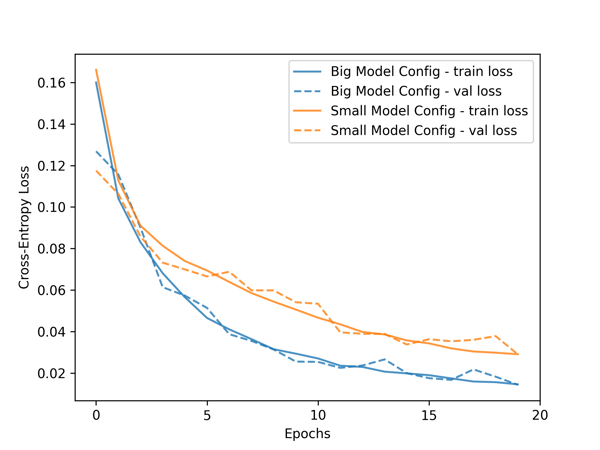
Figure 2. Classification Model Train & Validation Accuracy Curves
Conclusion and Summary Thoughts
As demonstrated by the measured results, the large on-chip memory and meta-pipeline execution of SambaNova’s RDA results in significant performance advantages over GPUs in both training and inference of LSTM and GRUs by overcoming challenges in “sequential computation on parallel processing”.
In real world applications, these performance advancements have the potential for significant impact across several industries for language modeling, text generation, speech and image recognition, time-series prediction, call center analysis, and many other applications and domains.