Premium inference is designed to solve the real problem that agents run into at scale. Agentic systems do not answer one prompt and stop. They reason, call tools, query databases, compile code, invoke sandboxes, validate results, and return to inference again and again until the work is done.
That is why the bar for premium inference has to be so high: decoding at roughly 200+ tokens per second on trillion-parameter-class models while staying efficient enough to fit real deployments. Fast decode, support for the largest models, practical chip footprint, and energy-efficient deployment are the core requirements.
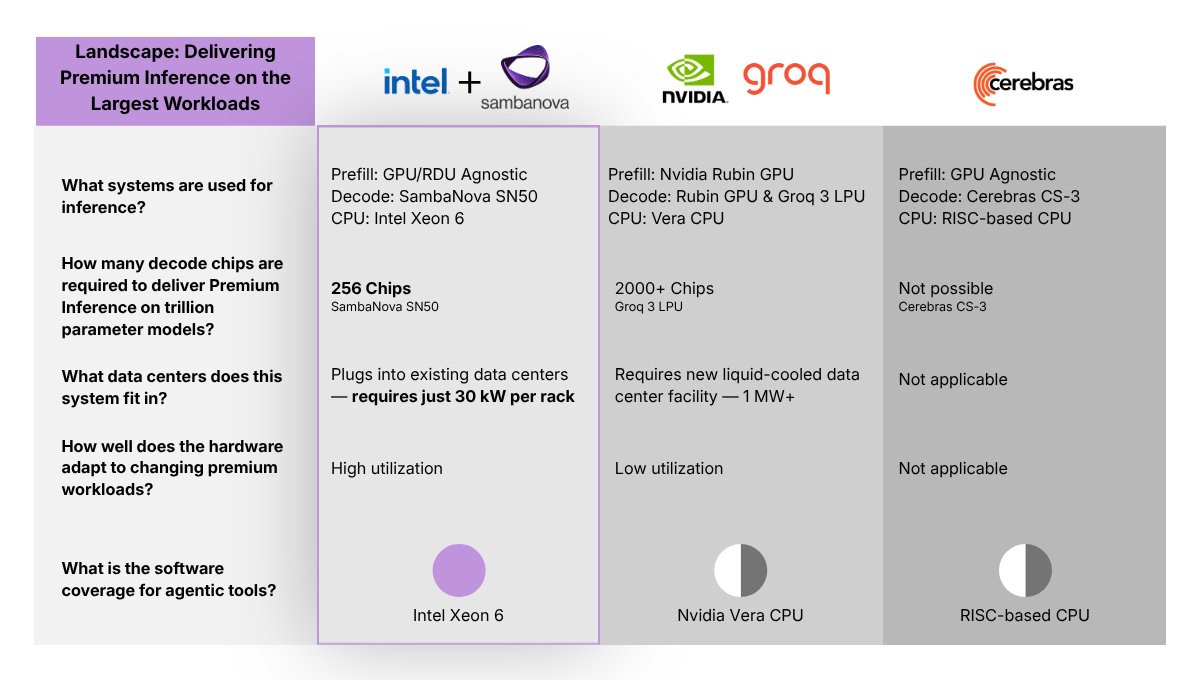
Meeting that bar takes more than one processor. It takes a blueprint. GPUs handle compute-bound prefill. RDUs handle fast decode. CPUs play two roles around the model: as the host CPU, they prepare data and orchestrate execution between GPUs and RDUs; as the action CPU, they run the agent frameworks, compilers, sandboxes, vector databases, APIs, and enterprise systems that make agents useful in production.
That is the blueprint behind SambaNova’s announcement with Intel. Together, the two companies are bringing a heterogeneous inference design to enterprises, cloud providers, and sovereign AI programs that need premium inference for real agentic workloads.
Why the Split Between Prefill and Decode Matters
The reason heterogeneous hardware matters is simple: prefill and decode are different jobs.
As we wrote in Solving the Decode Bottleneck: Why Agentic Inference Needs Hybrid Hardware, prefill is compute-bound KV-cache construction, which is why GPUs are well matched to it. Decode is different. It is memory-bound, dominated by token-by-token generation, and it is the bottleneck users actually feel in long agentic workflows.
That distinction matters even more in long agentic chains. Agents revisit prompts, return after tool calls, reuse context, and often switch models across many turns. In that environment, prompt caching becomes a practical way to reduce prefill compute, while fast decode is what keeps the system moving once generation starts.
This is where SambaNova’s RDU architecture matters most. RDUs are built to keep token generation flowing on large models by attacking the data-movement bottleneck in decode. That is why decode speed, model scale, and efficiency all sit at the center of the premium inference story.
Why CPUs Matter in Agentic Systems
Agents need CPUs for two reasons: to orchestrate inference and to execute the work around inference.
The host CPU prepares data, manages routing and queueing, coordinates accelerators, and runs the orchestration frameworks that connect GPU prefill to RDU decode. The action CPU executes the work agents trigger outside the model itself: compiling and running code, querying vector databases, accessing enterprise systems, enforcing policies, and validating results in environments that mirror production.
In the blueprint SambaNova announced, Intel Xeon 6 is both the host CPU and the action CPU around SambaNova RDUs. Under the agreement, SambaNova is standardizing on Xeon 6 as the host CPU paired with RDUs as the inference backbone.
Those roles show up directly in agent workloads. When a coding agent generates code, that code still has to be compiled and run before the system can move to the next step. Faster LLVM compilation means Daytona-style sandboxes can compile agent-generated code faster, return results faster, and send the agent back into the next inference turn sooner. The same logic applies to retrieval-heavy workflows: faster vector database performance helps agents fetch context, ground their answers, and keep multi-step tasks moving.
OpenClaw and Daytona Show Demand for This Blueprint
OpenClaw makes the latency problem visible. As we showed in The OpenClaw x SambaNova Playbook for Agentic Workflows, agent performance breaks when every planning step, tool call, test run, and retry pays a latency tax. Daytona shows the other side of the same problem: Once agents generate more code, the system needs more secure sandboxes and faster CPU-side execution to keep up.
As we showed when we launched our Agents demo in this blog, secure sandboxes powered by Daytona are part of what turns an agent from a chat experience into a system that can produce polished artifacts and take action. Put those two proof points together and the agentic deployment blueprint becomes clear.
The strongest systems are not the ones asking one chip to do everything. They are the ones assigning the right work to the right layer.
The Bottom Line
Premium inference for agentic AI is not just a benchmark number. It is the ability to decode at premium speed on trillion-parameter-class models, do it efficiently enough to stay deployable, and support the software stack agents need around the model.
Enterprises do not need one chip to do everything. They need GPUs for compute-bound prefill, SambaNova RDUs for fast decode, and CPUs as the host and action layer for agents.
And that is exactly the blueprint SambaNova and Intel are partnering to deliver to inference providers, enterprises, and sovereign AI programs.