The problem with single-model infrastructure in an agentic AI world
Traditional enterprise AI infrastructure was designed for a simpler era: Deploy one large model per node, scale horizontally, and hope latency and infrastructure costs remain acceptable. That assumption breaks down quickly for modern agentic AI workflows, where multiple large language models (LLMs) collaborate in a single request path.
Tasks like validation, tool selection, retrieval, reasoning, and synthesis often require different models with different strengths, invoked sequentially or conditionally. When each model lives on separate hardware—or worse, separate clusters — teams face compounding latency, operational complexity, and runaway infrastructure costs. The misconception is that bigger GPUs or more nodes solve this. In reality, the bottleneck is architectural: AI systems need infrastructure that treats multiple models as a first-class, co-resident workload.

Model bundling as the foundation for agentic AI systems
Model bundling is the practice of deploying multiple LLMs simultaneously on the same physical node and switching between them at runtime as part of a single application workflow. In SambaStack, a model bundle is defined declaratively using a Kubernetes manifest that lists the models — using customer-owned checkpoints if desired — that should be co-deployed on a node. Once applied, each model is exposed through an OpenAI-compatible inference API, making it straightforward to integrate with agent frameworks like LangGraph, LangChain, CrewAI, or custom orchestration layers.
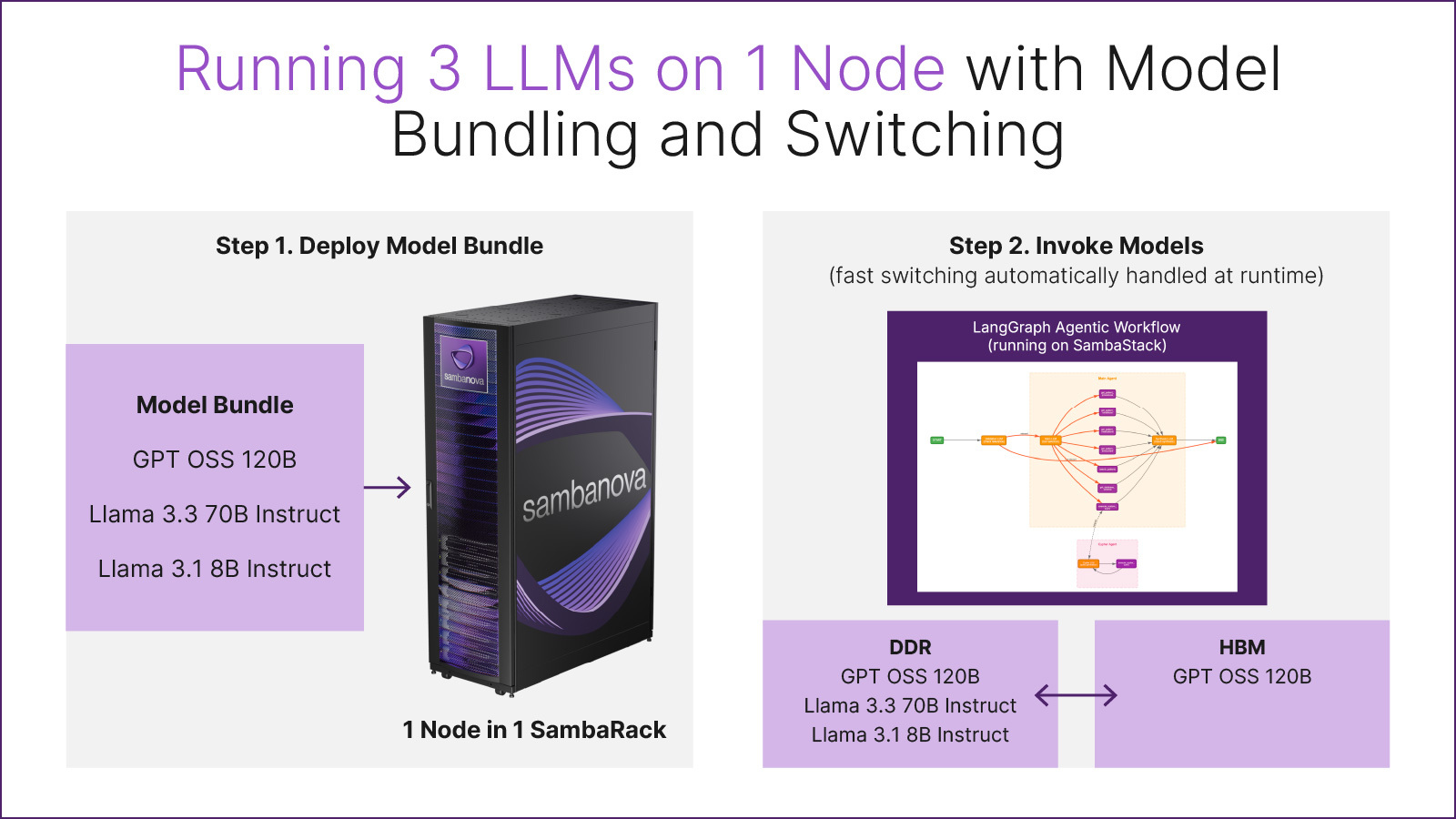
Under the hood, SambaNova’s Reconfigurable Dataflow Unit (RDU) architecture enables this approach. Models are staged in DDR memory and dynamically loaded into high-bandwidth memory (HBM) as needed, allowing microsecond-scale model switching during inference. This is fundamentally different from GPU-based systems, where context switching between large models often requires expensive reloads or dedicated hardware. A single SambaNova node — composed of eight AI servers in a rack with up to 1 TB of HBM — can hold and rapidly switch between multiple frontier-scale models, enabling complex agentic workflows to execute end-to-end on one node.
What this means for enterprises building real-world AI applications
For practitioners, model bundling collapses what used to be a distributed systems problem into a single-node execution model. Agentic workflows that previously required network hops between services can now execute locally, reducing tail latency and simplifying debugging and observability. In practice, this means faster responses, more predictable performance, and significantly lower infrastructure overhead for multi-model applications.
From an enterprise perspective, the implications are even larger. With SambaStack, organizations can deploy bundled models on-premises, in private or air-gapped environments, or in a hosted SambaNova-managed environment while retaining full operational control. This is critical for regulated industries where sensitive data must never leave the enterprise network.
The system switched across four LLM calls in just over two seconds end-to-end, while querying a Neo4j graph database and generating custom Cypher queries as needed. The same architectural pattern applies to finance, defense, cybersecurity, and any domain where multi-step reasoning over proprietary data is required.
Demonstration of end-to-end agentic GraphRAG workflow running on a single node with SambaStack
From GraphRAG to production-scale inference on SambaStack
Agentic GraphRAG combines retrieval-augmented generation with graph databases, enabling AI systems to reason over entities and relationships rather than flat documents. In the demonstrated workflow, LangGraph orchestrated multiple agents: one for input validation, another for tool selection and reasoning, and a specialized agent for text-to-Cypher generation against a Neo4j graph. Each agent used a different LLM optimized for its task, all deployed as a single model bundle on SambaStack.
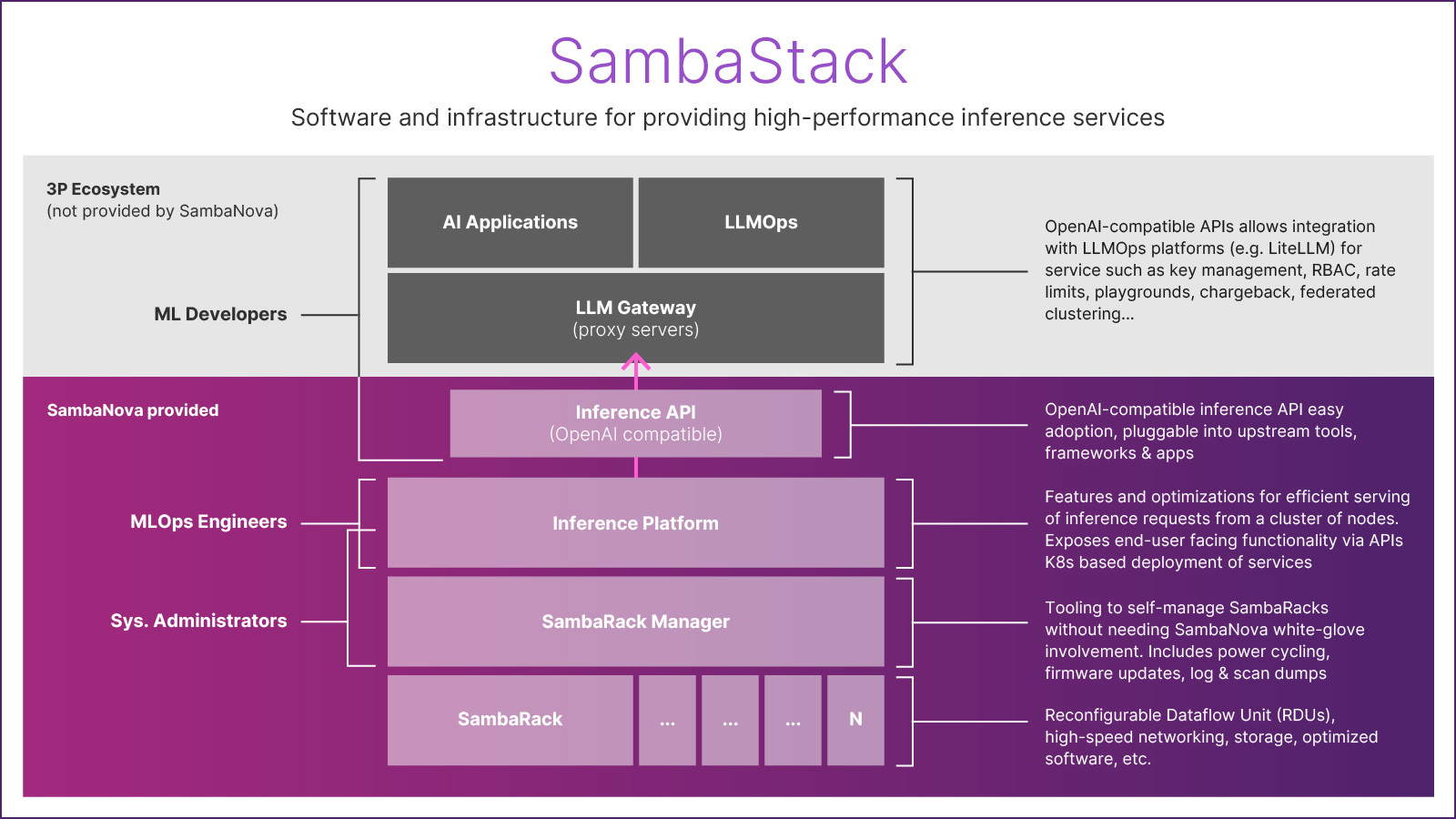
This workflow highlights the practical value of SambaStack’s design. The SambaRack Manager allows customers to manage their own infrastructure without SambaNova involvement, while Kubernetes-native deployment supports rapid iteration and scaling. Even if an application can be deployed on a single rack, horizontal scaling with multiple racks allows you to better serve workloads that require high concurrency. Because the inference APIs are OpenAI compatible, existing applications and Large Language Model Operations (LLMOps) tooling can be reused with minimal changes. Developers can track and observe agent and model calls using integrations like LangSmith, accelerating the path from prototype to production.
How to get started with bundled models on SambaStack
Ready to run multi-model, agentic AI workloads without multiplying your hardware footprint? Get in touch with SambaNova to explore SambaStack and see how RDUs can better help you manage your AI footprint.