In the rapidly evolving landscape of artificial intelligence, SambaNova has once again demonstrated its commitment to innovation and performance. Just days after Meta's release of the Llama 3.3 70B model, SambaNova has already optimized and released the model on its RDU hardware architecture. It is available today for developers to use on SambaNova Cloud running at speeds over 400 tokens/ second as independently verified by Artificial Analysis.
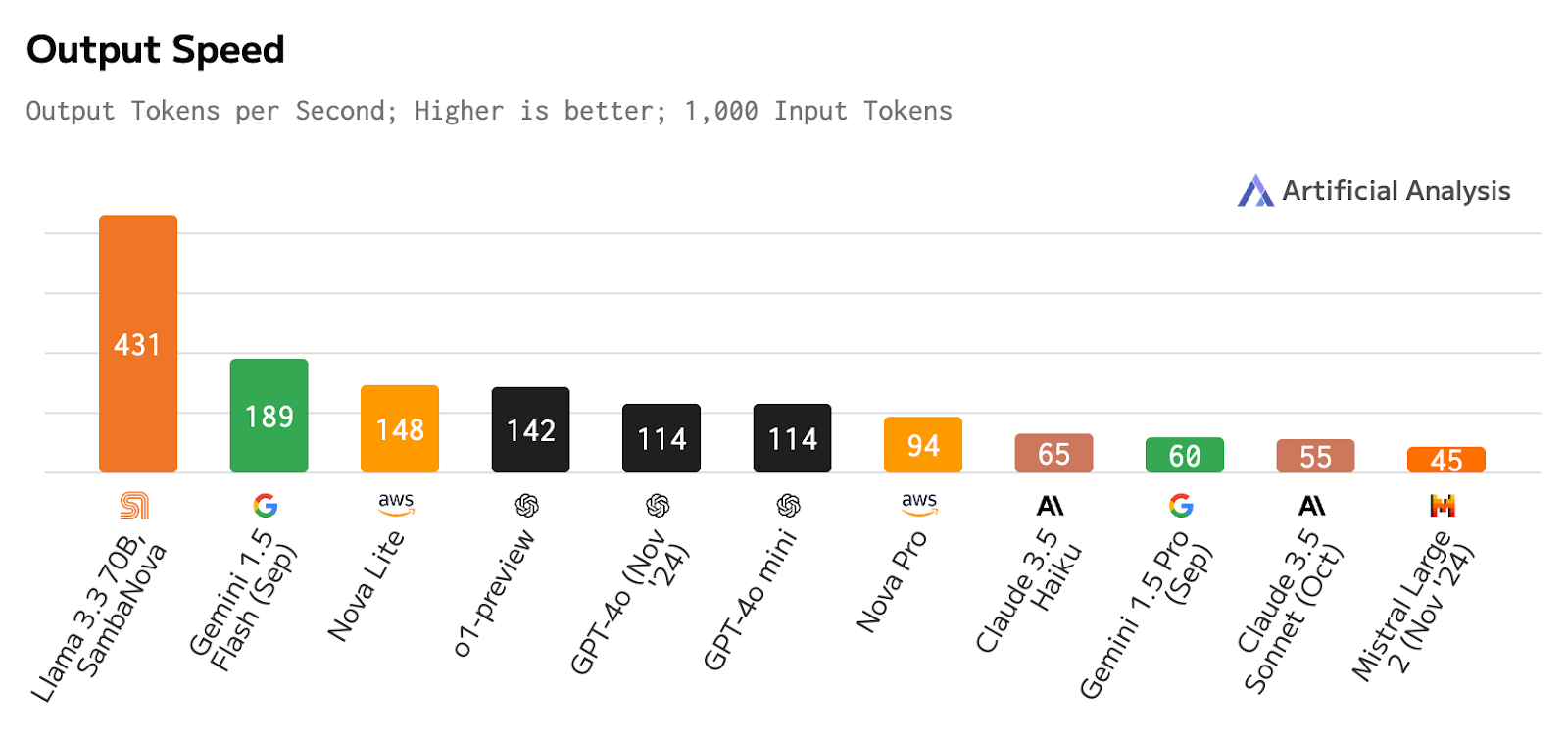
Artificial Analysis has independently benchmarked SambaNova as providing Meta's Llama 3.3 70B model at 430 tokens/s on their cloud API endpoint.
Meta's new Llama 3.3 70B demonstrates intelligence comparable to other leading models including OpenAI's GPT-4o and Mistral Large 2. This provides a clear upgrade path for users of Llama 3.1 70B, the most popular open-source model. It is also an opportunity for many users of Llama 3.1 405B to access similar intelligence at greater speed and lower price, though specific use-case testing is recommended.
SambaNova's new endpoint which provides this level of intelligence at speeds many times greater than comparable proprietary model APIs presents a compelling offer for developers, particularly those who have speed-dependent use-cases such as those who are building real-time or agentic applications."
- George Cameron, Product lead, Artificial Analysis
Overall Model Quality
Meta's Llama 3.3 70B model has been enhanced using advanced post-training techniques, resulting in significant improvements across various domains such as reasoning, mathematics, and general knowledge. For developers already using Llama 3.1 70B, it will be natural to upgrade to using Llama 3.3, which now runs faster and more accurately than the prior model. For those using other proprietary foundation models, now is a great time for them to switch to using Llama 3.3 70B, which is highly accurate and runs faster than most other providers other than today using GPUs.
While Llama 3.3 70B is definitely much closer in terms of accuracy to Llama 3.1 405B, if you need the best open source foundation model to handle your tasks, we still recommend evaluating 405B on SambaNova and seeing if that better serves your use cases.
As Meta continues to push the bounds of what is possible with Open Source models, we will continue to support and optimize these models to run even faster and more efficiently on our RDU hardware for developers!
What It Means for Developers
SambaNova currently offers a large context length on the Llama 3.3 70B at 4K input tokens, which is sufficient for most common RAG and Function Calling Use Cases. Developers can start using the model today in those types of workloads and combine it with many of the other models on our cloud for Agentic Applications. For example, if you are developing a Coding Agent (see an example of one from our friends at Blackbox), you can use Llama 3.3 to decompose a coding task into many problems and then have another model like our recently launched Qwen-32B-Coder model, write the code even faster!

Getting Started
Developers and enterprises can now access the Llama 3.3 70B model through the SambaNova Cloud developer console. Here, you can obtain a free API key and start building your AI-powered applications immediately.
For those needing higher rate limits, consider applying for our Startup Accelerator Program that we just launched, where you will get access to these models and more even earlier.