Document Visual Question Answering (DocVQA) is a core capability of Vision Language Models (VLMs) that is essential for enterprise deployments of VLMs. It is generally more nuanced than simple classification or summarization tasks, and as such is generally measured with n-gram similarity metrics such as BLEU 10, ANLS 11, or exact-match (EM). On the namesake DocVQA dataset 1, modern VLMs such as Claude 3.5 Sonnet, Llama 3.2 90B and Qwen-2.5 72B are performing at or above human-level at 94.4 ANLS.
However, enterprises around the world process documents in more than just English. The performance of modern VLMs on this task in non-English languages is significantly less well-understood. To understand the needs of our customers, we evaluated frontier closed- and open-sourced VLMs on the Japanese version of this task with JDocQA 2, a dataset curated by researchers at Nara Institute of Science and Technology, RIKEN, and ATR in Japan.
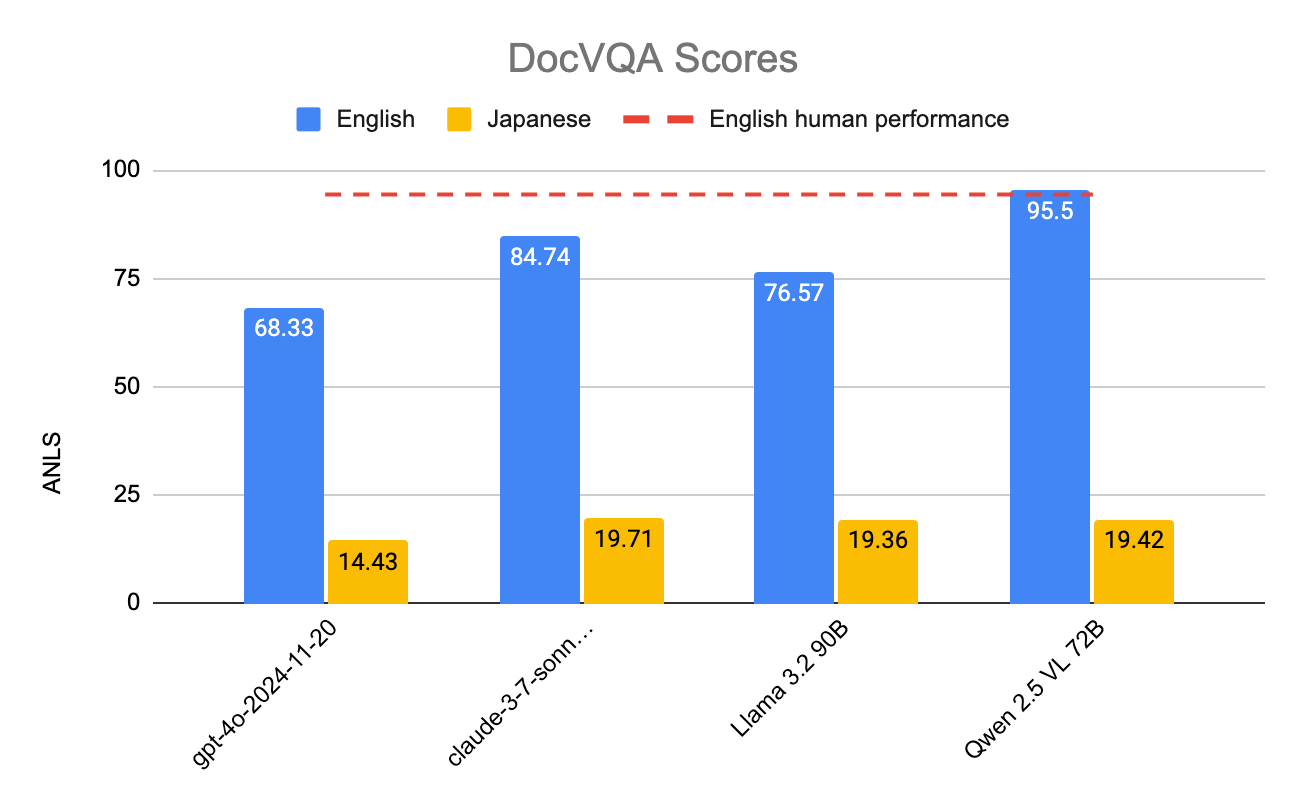
It’s apparent that many of these models are significantly worse at the Japanese version of this task than the English, despite many of them claiming strong multilingual performance. However, there is more nuance to this supposed discrepancy than meets the eye. In this blogpost, we’ll dive deeper into why these models perform so much worse in Japanese, why we should evaluate with LLM-Judge instead of ANLS, and what models worked for us as an LLM-Judge.
DocVQA vs JDocQA
Let’s take a look at an example from each dataset to understand why the difference in performance is so drastic. Take this sample from the DocVQA validation split:
Question: What is the name of the company?
Answers: [“itc limited”, “ITC Limited”] 
The answer to the question is in big bold letters at the top, as well as in the header of the document. (provide example answers from models). This particular example is reflective of the rest of the dataset; the dataset is meant to be an extractive VQA task, where the ground truth answers are present, verbatim, in the text (see 1 page 3, Section 3.1 Data Collection, Questions and Answers). So this task is really a test of the model’s OCR and instruction following abilities.
In contrast, let’s look at an example from the JDocQA training split:
Question: 12月24日の選挙当日に外出の予定が入っており、投票所へ行けないのですがどうしたらいいでしょうか?解答は自由に記述してください。
(I have plans to be out on the day of the election on December 24th, and I can't go to the polling station. What should I do? Please write your answer freely.)
Answer: 投票日に投票所へ行けない場合は、市内2か所の期日前投票所にて投票することができます。
(If you are unable to make it to the polling station on the election day, you can vote at one of two early voting stations in the city.)
In this particular example, answering this question requires careful reading and interpretation of the entire text of the document, and there is no verbatim wording of the ground truth answer in the document text. This open-ended type of VQA problem is one of 5,827 such examples in the dataset 2, over 50% of the dataset. The other 50% consists of Yes/No, Factoid, and Numerical questions, which may actually contain the verbatim ground truth answer in the document.
So we can see that, in one sense, JDocQA is a harder dataset than DocVQA, disregarding the language barrier. But even if VLMs got every open-ended question in JDocQA wrong, shouldn’t there be another 50% of the dataset that they should be achieving higher scores in?
This discrepancy can be further explained by our choice of evaluation metric. In the next section, we’ll discuss ANLS and how it fails to capture the nuances of ground truth answers in JDocQA.
ANLS
Average Normalized Levenshtein Distance (ANLS) is the standard evaluation metric for visual question-answering (VQA) tasks proposed by Mathew et al. in the DocVQA paper 1. It is typically reported as a number between 0 and 1, where 0 represents no similarity to a ground-truth answer and 1 represents a perfect match. Intermediate values measure how close, in terms of edit distance, a proposed answer is to the ground truth.
As for why ANLS might be hiding model performance, let’s look at an example completion from the JDocQA validation set:
Question: 富士市の教育ローン(富士市勤労者教育資金貸付制度)の利率、融資限度額、貸し付け期間はどうなっていますか?
What are the interest rate, loan limit, and loan period for Fuji City's education loan (Fuji City Workers' Education Fund Loan System)?
Ground truth answer: 富士市の教育ローン(富士市勤労者教育資金貸付制度)の利率は年1.70%、融資限度額は300万円、貸付の期間は5年以内で、勤労者やその家族の、高校・大学などへの進学時や在学中の教育費用を、市が静岡県労働金庫と協調して貸し付けます。
Fuji City's education loan (Fuji City Workers' Education Fund Loan System) has an interest rate of 1.70% per year, a loan limit of 3 million yen, and a loan period of up to 5 years. The city cooperates with the Shizuoka Prefectural Labor Bank to provide loans to workers and their families for the educational expenses of entering high school, university, etc. and while they are in school.

Llama 3.2 90B Instruct provides the following answer:
富士市の教育ローン(富士市勤労者教育資金貸付制度)の利率、融資限度額、貸し付け期間は以下の通りです。
* 利率:年1.70%
* 融資限度額:300万円
* 貸し付け期間:5年以内
この制度は、富士市に在住する学生や在学中の家族を対象に、教育費用の資金援助を目的とした制度です。
The interest rate, loan limit, and loan period for Fuji City's education loan (Fuji City Workers' Education Fund Loan System) are as follows.
* Interest rate: 1.70% per year
* Loan limit: 3 million yen
* Loan period: up to 5 years
This system is intended to provide financial assistance for educational expenses for students living in Fuji City and their families currently enrolled in school.
This seems like a pretty reasonable and correct answer when compared to the ground truth: it mentions all 3 points of a 1.7% interest rate, a loan limit of 3 million yen, and a loan period up to 5 years. If asked for a binary decision on whether the answer is correct, a human would surely give a 1 instead of a 0. However, this answer only gets an ANLS score of 0.3945 (39.45 if we multiply by 100 for comparison to the chart above). Since ANLS is generally thresholded by 0.5, it ends up being a score of 0!
When we look through the rest of the dataset, we notice that not only do correct answers get a low ANLS score, there are also wrong answers that obtain a high ANLS score:
Question: 各地区まちづくりセンターでの出張受付の表によると、2月18日(木)では、浮島で行われますか。
According to the on-site registration table at each district urban development center, will the event be held at Ukishima on Thursday, February 18th?
Ground truth answer: いいえ。
No

Llama 3.2 90B Instruct answer: はい。
Yes.
Here, we can see the model is clearly getting a yes or no question wrong. Despite this, this answer nets an ANLS score of 0.5, which is above the correctness threshold! This despite the question being denoted a “yes-or-no” question, which should be easily compared against using automatic metrics. So what can we do? How can we approach human-level judgments of correctness? In the next section, we’ll discuss how LLM-Judge can be used to solve this issue.
Aside: ANLS explanations
Why does the second, incorrect example get a higher ANLS score? Let’s see how ANLS is defined:
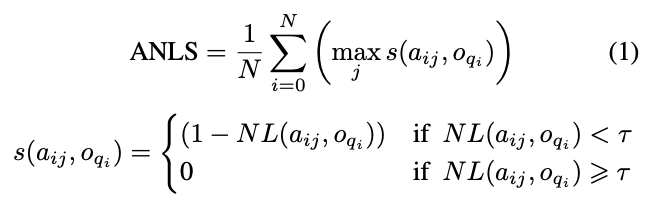
The outer summation is over N questions in a dataset, so let’s just focus on the metric s over the ground truth answer aij and a candidate answer oqi. NL is the normalized Levenshtein distance 12, or edit distance between the 2 strings. This is essentially the ratio between the minimum number of edits between aij and oqi, and the maximum length of the two strings.

For the second example, we have
These answers are short enough to make it clear that the Levenshtein distance is 2. The max length is len(aij) = 4, so the ANLS for this single instance is
We similar calculation for the second example, although the Levenshtein distance and max length are less obvious:
We can interpret it this way: edit distance to get from the predicted answer to the ground truth, as a ratio compared to the string length, was smaller for the yes-or-no example compared to the “富士市の教育” example.
LLM-Judge as a metric
LLM-Judge was popularized in 2023 as a method to evaluate alignment with human preferences 3567. In the open-ended task of selecting human preferences amongst chat completions, Zheng et al. found that, while the method is still subject to potential bias and error depending on the LLM, LLM-Judge matched 80% of human annotations while being more nuanced and flexible than BLEU score.
In the MT-bench paper, authors use LLM-Judge for pairwise preference ranking ([A] better than [B]) or Likert score rating (rate this response on a scale of 1-10). Since then, LLM-Judge has been widely adopted for a variety of use cases, including for evaluating model summaries 4, detecting gender bias 8, and in evaluating safety refusal 9.
We propose using LLM-Judge as a proxy for the simple question: given a question and answer pair, does the provided response actually answer the question? Compared to metrics like ANLS, EM, and BLEU score, this can encompass the varied ways that a model might correctly answer the question without much n-gram overlap (e.g. 1万 vs 10000, or “page 1” vs “page one”). Conversely, false positives are also completely possible, with high ANLS/BLEU score attached to “page 3” when “page 1” is the answer. We use the following prompt template:
I am going to give you a question, the answer to the question, and model's answer to the question. You are to tell me if the model is correct. Respond [[1]] if correct and [[0]] if incorrect. Then give me an explanation of your judgement. Here is the question:
{question}
Here is the answer to the question:
{ground_truth_answer}
Here is the model completion:
{model_answer}
Judgement:
Using this prompt template, we extract the [[0]] or [[1]] from the LLM-Judge response to mark a model’s response and correct or incorrect. We calculate the mean score for JDocQA across the GPT-4o, Claude 3.7, Llama 3.2 90B Instruct, and Qwen 2.5 VL 72B using either GPT-4o or Llama 3.1 405B Instruct as the LLM-Judge.

We can see that ANLS appears to significantly underestimate the performance of frontier models on the Japanese question answering task. In fact, frontier models appear to get about 45% of the questions correct, significantly higher than the 20% that ANLS would let on.
Comparing to DocVQA
So are modern VLMs really underperforming on document VQA in non-English languages? We can’t really compare the ANLS score of DocVQA to the LLM-Judge score of JDocQA fairly. So let’s calculate the LLM-Judge score of each of the above models for DocVQA as well.


Depending on the LLM-Judge used, DocVQA scores for English are either around the same or up to 10 points higher when reporting with LLM-Judge as the metric. When compared to the performance using the same metric on JDocQA, VLMs are generally 2x better at the simpler English task.
Conclusions
In summary: although we cannot blindly compare the immediate performance of frontier VLMs on English DocVQA and JDocQA, even after accounting for the extra complexity of the Japanese task and switching our metric, it’s clear that modern VLMs still have a ways to go when processing images in other languages. However, when we compare the performance of frontier models on even the English task as close as a year ago, the signs are encouraging: the field is improving rapidly, and we should have production ready models for more than just English documents soon. We’ll just note that choosing the right evaluation dataset and evaluation metric will go a long way in helping us get there even faster.
Aside: GPT-4o vs the field
In many of our internal training experiments to break new ground in this field, we choose to use Llama 3.1 405B Instruct on the SambaNova Cloud over GPT-4o as an LLM-Judge to evaluate new checkpoints. This is for a variety of reasons:
- Speed: when using 405B Instruct on the SambaNova cloud, running LLM-Judge on about 800 examples of JDocQA takes about 30 minutes, when compared to 50 minutes using GPT-4o on Azure
- Reliability: depending on the dataset, GPT-4o may refuse to answer questions due to OpenAI content restrictions, and may even fail to follow the [[1]] and [[0]] format of the LLM-Judge prompt. 405B, as an open source model, does not have any such content restrictions, and never failed to provide a correctly formatted output
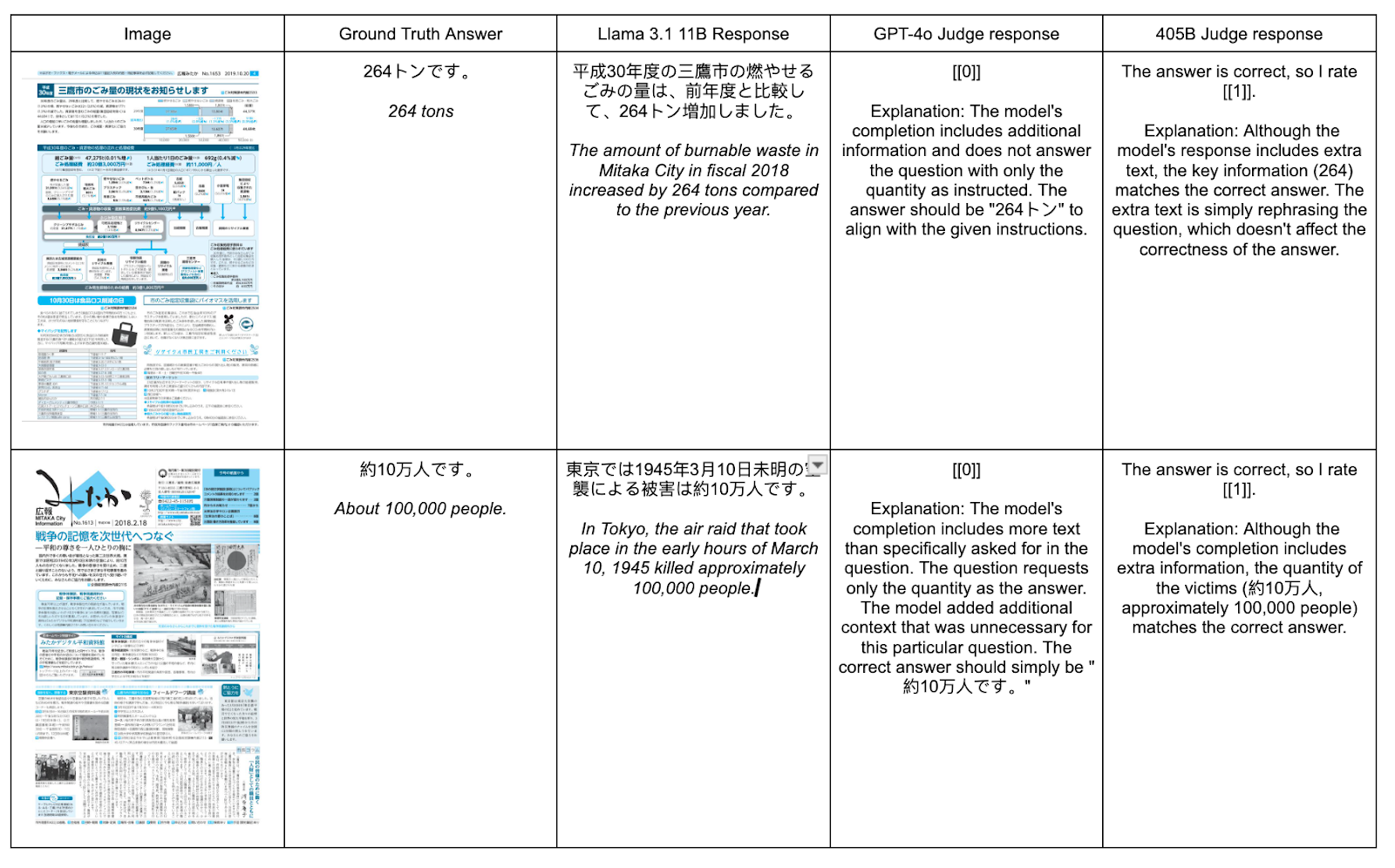
- GPT-4o tended to be overly harsh as a judge, which is reflected in its lower scores compared to 405B. See some examples below where GPT-4o marks an answer as incorrect, despite 405B (and human common sense) saying otherwise
Appendix: Comparisons to Human Judgments
While it is infeasible to compare human judgments against our ANLS, GPT4Judge and 405BJudge for every model and every example, we show these comparisons for the first few examples from the JDocQA subset. While all three metrics have around the same Spearman’s correlation with the human judgments (0.41, 0.41, and 0.36 respectively), it’s worth noting that with such a small sample, the p-values are very high as well (0.24, 0.24 and 0.31 respectively).
A few important observations:
- For 6/10 of the ratings where a human gave a 0, all other metrics reported 0 as well, suggesting high precision for wrong answers
- For 4/10 ratings where a human gave a 1, all other metrics also reported a 0, except for the first instance where 405BJudge also reported a 1

|
Ground Truth Answer Llama 3.1 11B Response Human Score: 1 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 1 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 1 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 (The text specifically calls out the two examples in the ground truth answer) ANLS: 0 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 1 ANLS: 1 GPT-4o Judge response 405B Judge response |

|
Ground Truth Answer
Llama 3.1 11B Response
Human Score: 0 ANLS: 0 GPT-4o Judge response 405B Judge response |
References
1 Mathew, Minesh, Dimosthenis Karatzas, and C. V. Jawahar. "Docvqa: A dataset for vqa on document images." Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021.
2 Onami, Eri, et al. "JDocQA: Japanese document question answering dataset for generative language models." arXiv preprint arXiv:2403.19454 (2024).
3 Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2023): 46595-46623.
4 Gao, Mingqi, et al. "Human-like summarization evaluation with chatgpt." arXiv preprint arXiv:2304.02554 (2023).
5 Li, Junlong, et al. "Generative judge for evaluating alignment." arXiv preprint arXiv:2310.05470 (2023).
6 Zhu, Lianghui, Xinggang Wang, and Xinlong Wang. "Judgelm: Fine-tuned large language models are scalable judges." arXiv preprint arXiv:2310.17631 (2023).
7 Liu, Yuxuan, et al. "Calibrating llm-based evaluator." arXiv preprint arXiv:2309.13308 (2023).
8 Kumar, Shachi H., et al. "Decoding biases: Automated methods and llm judges for gender bias detection in language models." arXiv preprint arXiv:2408.03907 (2024).
9 Xie, Tinghao, et al. "Sorry-bench: Systematically evaluating large language model safety refusal behaviors." arXiv preprint arXiv:2406.14598 (2024).
10 Papineni, Kishore, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002.
11 Biten, Ali Furkan, et al. "Scene text visual question answering." Proceedings of the IEEE/CVF international conference on computer vision. 2019.