Last month, the SambaNova team, in partnership with Stanford and UC Berkeley, introduced the viral paper Agentic Context Engineering (ACE), a framework for building evolving contexts that enable self-improving language models and agents. Today, the team has released the full ACE implementation, available on GitHub, including the complete system architecture, modular components (Generator, Reflector, Curator), and ready-to-run scripts for both Finance and AppWorld benchmarks. The repository provides everything needed to reproduce results, extend to new domains, and experiment with evolving playbooks in your own applications. Feel free to try it out... we’d love your feedback and contributions!
ACE changes how AI learns — instead of updating weights, it grows its memory, storing lessons from every win and mistake. Like an AI that journals after each task, it reflects, notes, and reasons better next time, turning static models into experience-driven, self-improving systems. ACE consistently outperforms strong baselines including +10.6% on agentic benchmarks and +8.6% on domain specific benchmarks, while significantly reducing latency and rollout cost.
1. Why Context Engineering
Context engineering has rapidly become a central theme in building capable, reliable, and self-improving AI systems. It has gained attention across both research and industry, from Anthropic’s guidebook on context engineering [1], to mem0’s and Letta’s development of persistent memory layers for AI agents [2,3], to Databricks’ enterprise agent that integrates prompt optimization [4].
At its core, context engineering arises from the need to dynamically adapt and customize AI systems over the long term, beyond what fine-tuning alone can achieve. This includes remembering a user’s personal preferences, maintaining enterprise records, recalling prior strategies or lessons learned from interaction with environments, etc. The term context can take many forms — prompts, memory states, or input structures — but the fundamental challenge remains the same: How to systematically engineer inputs that enable AI systems to remain capable, consistent, and reliable over time.
Two recent trends suggest that context engineering is increasingly well-supported over time, making it a “friend with time” as both models and systems evolve.
- Advances in long-context modeling
Large language models (LLMs) are becoming increasingly capable of handling long and complex contexts, both in terms of extended context window sizes and improved recall accuracy — demonstrated, for example, by benchmarks such as needle-in-a-haystack.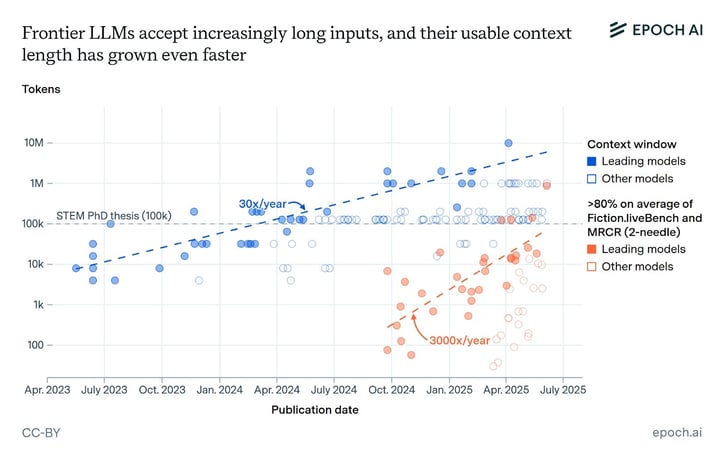
- Progress in long-context serving infrastructure
Inference systems are now better equipped to serve long-context workloads efficiently. Recent advances include optimized KV cache transfer and storage mechanisms (e.g., LMCache [5], Mooncake [6]) and high-performance KV cache compression libraries such as NVIDIA’s KVPress [7].
2. ACE: Agentic Context Engineering
2.1 Two Limitations in Existing Methods
Despite the early promise delivered by context adaptation, we observe two major limitations in existing methods.
- The Brevity Bias
We observe that many context optimization approaches demonstrate the tendency to collapse toward short, generic prompts. Research papers like The Prompt Alchemist [8] document this effect in prompt optimization for software test generation, where iterative methods repeatedly produce near-identical instructions (e.g., "Create unit tests to ensure methods behave as expected"), sacrificing diversity and omitting domain-specific details.
Humans and LLMs have different advantages when handling contexts. Humans benefit from concise, higher-level summarization, while language models increasingly benefit from detailed, dense context (as demonstrated by recent trends in research [9, 10, 11]).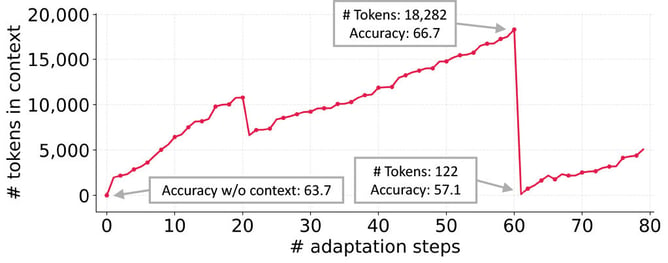
- Context Collapse
We observe the phenomenon of “context collapse” — iterative rewriting of context could lead to sudden shrinkage of the context into shorter, less informative summaries, resulting in severe performance degradation. As demonstrated by the figure below, the context at step 60 contained 18,282 tokens and achieved an accuracy of 66.7, but at the very next step it collapsed to just 122 tokens, with accuracy dropping to 57.1 — worse than the baseline accuracy of 63.7 without adaptation.
2.2 Core Principles of ACE
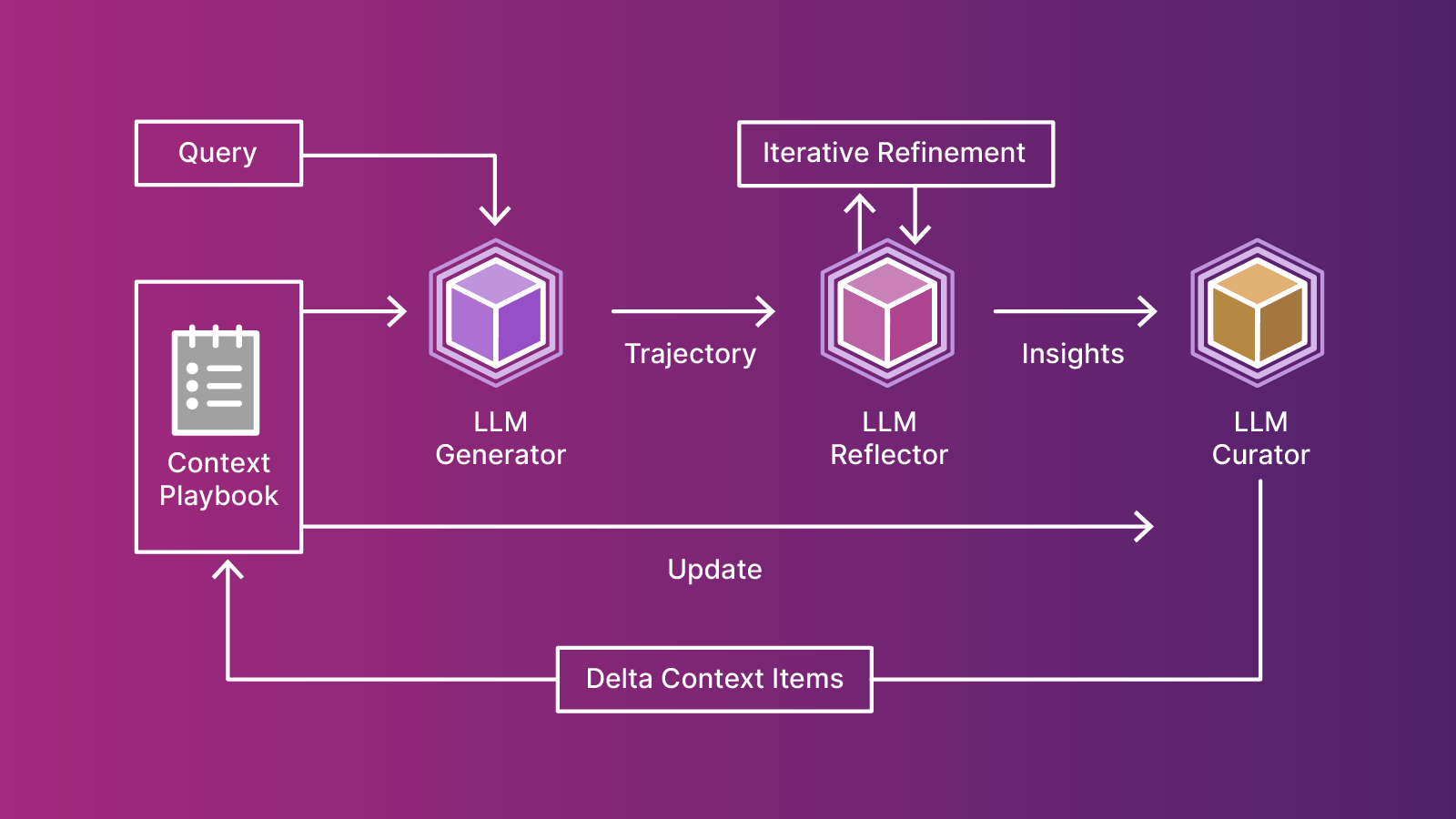
We argue that contexts should function not as concise summaries, but as comprehensive, evolving playbooks — detailed, inclusive, and rich with domain insights.
ACE is designed to achieve this goal of comprehensive and evolvable context. The ACE framework features an agentic architecture that separates the responsibility across three components:
- Generator — Produces reasoning trajectories and identifies useful context items.
- Reflector — Analyzes successes and failures, and extracts concrete insights.
- Curator — Organizes insights into structured, incremental context updates.
Note that ACE is not the first work to adopt this type of architecture. Prior work, like Dynamic Cheatsheet [12], features a Generator-Curator framework for managing adaptive memory as context. The key innovation of ACE as compared to prior work is to enable the scalable growth of contexts in an efficient way, avoiding issues like the brevity bias and context collapse, as well as the high overhead of context update.
ACE adopts the following key recipes for efficient and scalable growth of context:
- Incremental, structured update
ACE features incremental updates of context in the format of small “delta” updates. Instead of rewriting the entire context, the Curator produces a small piece of context that gets merged into the existing context. This merging operation is achieved via non-LLM components for stability. Further efficiency and capability can be unlocked through (1) parallel learning of multiple “delta” contexts from different input samples, and (2) multi-epoch adaptation, in which the same input samples are revisited to progressively extract more insights. - Grow-and-refine
Besides facilitating the growth of context as a first-class principle, ACE periodically refines the context to make it compact and knowledge-dense. A de-duplication step merges context bullets with high semantic similarity scores to reduce redundancy. Based on the need of application, this step can run either lazily (only when necessary) or proactively.
.jpg?width=960&height=640&name=ace-context-1%20(1).jpg)
Figure: Example ACE-Generated Context on the AppWorld Benchmark (partially shown).
2.3 Results and Findings
- Enabling High-Performance, Self-Improving Agents
ACE enables agents to self-improve by dynamically refining the input context. It boosts accuracy on the AppWorld benchmark by up to 17.1% by learning to engineer better contexts from execution feedback, without needing ground-truth labels. This allows a smaller, open-source model (DeepSeek-V3.1) to match the performance of the top-ranked proprietary agent (IBM CUGA with GPT-4.1) on the leaderboard. - Large Gains on Domain-Specific Benchmarks
On complex financial reasoning benchmarks, ACE delivers an average performance gain of 8.6% over strong baselines by constructing comprehensive playbooks with domain-specific concepts and insights. - Lower Cost and Adaptation Latency
ACE achieves these gains efficiently, reducing adaptation latency by 86.9% on average, while requiring fewer rollouts and lower token dollar costs.
3. Q & A
Q: Does ACE kill fine-tuning?
A: Short answer: No. We believe that fine-tuning is still crucial in aligning AI systems, reducing inference-time resource usage, etc. ACE offers a new perspective (orthogonal to fine-tuning) that adapts AI systems without changing weights, and could be particularly useful in these scenarios: (1) when the cost of fine-tuning is high, especially when updates are small and frequent, and (2) when model weights are not available (e.g. commercial LLMs), (3) when training data and ground-truth reward are not available, and (4) when concerns like selective unlearning (e.g. due to privacy laws), interpretability, etc. are important.
Q: How does ACE differ from prompt optimization methods like GEPA?
A: ACE does not conflict with methods like GEPA, and in fact, can be used jointly with existing prompt optimization methods. One example is that a solid system prompt can be learned with GEPA based on training data in the offline stage, assuming computation resource and adaptation latency are not concerns; ACE can be used during the online stage to further grow and refine the context, when ground-truth rewards might not be available and adaptation latency is a concern. Overall, the focus of ACE is to grow contexts in a scalable and efficient way, avoiding issues like the brevity bias and context collapse.
Q: What if the context window is exceeded?
A: Though not explicitly addressed in this work, ACE can be used in complementary to many other context management approaches. For example, when the context window limit is reached and something has to be dropped, ACE could benefit from existing methods in context compression, token dropping, etc. We take this as an important future direction, and we are working to evaluate how these approaches might affect ACE’s effectiveness.
Q: What are the limitations of ACE?
A: A potential limitation of ACE is its reliance on a reasonably strong Reflector: if the Reflector fails to extract meaningful insights from generated traces or outcomes, the constructed context may become noisy or even harmful. In domain-specific tasks where no model can extract useful insights, the resulting context will naturally lack them. This dependency is similar to Dynamic Cheatsheet [12], where the quality of adaptation hinges on the underlying model’s ability to curate memory. We also note that not all applications require rich or detailed contexts. Tasks like HotPotQA often benefit more from concise, high-level instructions (e.g., how to retrieve and synthesize evidence) than from long contexts. Similarly, games with fixed strategies such as Game of 24 may only need a single reusable rule, rendering additional context redundant. Overall, ACE is most beneficial in settings that demand detailed domain knowledge, complex tool use, or environment-specific strategies that go beyond what is already embedded in model weights or simple system instructions.
Building Your Own Applications with ACE
Developing with ACE is now extremely easy. Below is a quick start guide to help developers who clone our repo start building with ACE. The code contains a generator, reflector, and curator that continuously improve the playbook as mentioned above. You can read more about how to use ACE in the README included in the repo.
ACE is more than just a framework, but also a new paradigm: We believe that AI systems can be made smarter and better without changing its brain, but with smarter contexts. We would love to engage with the community to further explore this research direction, and make it more useful in practice.
Future Roadmap
We are currently working on the following aspects to make ACE more practical and usable.
- Support for more applications.
ACE could benefit a diverse set of applications, ranging from agentic AI to domain-specific problem solving. We are actively working to evaluate ACE on different types of applications, and we’d love to engage with the community to see what everyone wants to build with ACE. - Agent framework integration.
To make ACE easy to use, we plan to integrate ACE into mainstream agent frameworks as plug-in modules. For now, we are working on ACE integration into DSPy, and we will update the community on that in a few weeks. - Powering AI training with ACE.
We are actively exploring how ACE-generated contexts can be used in turn to train more powerful AI models via techniques like RLVR. We believe this could form a virtuous cycle: ACE produces contexts and rewards for training AI systems, while AI systems empower ACE to be more capable.
Citation
If you find our work helpful, please use the following citation.
@article{zhang2025agentic, title={Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models}, author={Zhang, Qizheng and Hu, Changran and Upasani, Shubhangi and Ma, Boyuan and Hong, Fenglu and Kamanuru, Vamsidhar and Rainton, Jay and Wu, Chen and Ji, Mengmeng and Li, Hanchen and others}, journal={arXiv preprint arXiv:2510.04618}, year={2025} }
References
[1] Anthropic, Effective context engineering for AI agents, 2025
[2] mem0, Universal memory layer for AI Agents, 2025
[3] Letta, Agent Memory: How to Build Agents that Learn and Remember, 2025
[5] LMCache, Accelerating the Future of AI, One Cache at a Time
[6] Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
[7] NVIDIA/KVPress: LLM KV cache compression made easy
[8] Shuzheng Gao, Chaozheng Wang, Cuiyun Gao, Xiaoqian Jiao, Chun Yong Chong, Shan Gao, and Michael Lyu. The prompt alchemist: Automated llm-tailored prompt optimization for test case generation. arXiv preprint arXiv:2501.01329, 2025.
[9] Tianxiang Chen, Zhentao Tan, Xiaofan Bo, Yue Wu, Tao Gong, Qi Chu, Jieping Ye, and Nenghai Yu. Flora: Effortless context construction to arbitrary length and scale. arXiv preprint arXiv:2507.19786, 2025.
[10] Yeounoh Chung, Gaurav T Kakkar, Yu Gan, Brenton Milne, and Fatma Ozcan. Is long context all you need? leveraging llm’s extended context for nl2sql. arXiv preprint arXiv:2501.12372, 2025.
[11] Mingjian Jiang, Yangjun Ruan, Luis Lastras, Pavan Kapanipathi, and Tatsunori Hashimoto. Putting it all into context: Simplifying agents with lclms. arXiv preprint arXiv:2505.08120, 2025.
[12] Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. arXiv preprint arXiv:2504.07952, 2025.