開発者およびエンタープライズ向け
DeepSeek、Llama、OpenAIなど、最先端のオープンソースモデルをSambaCloud上で活用し、数分で開発を開始できます。クラウドやオンプレミスで専用インフラを構築できるSambaStackにより、エンタープライズ規模への拡張も容易です。
詳細はこちら → 開発者およびエンタープライズ向け政府および
公共部門向け
SambaStack for Public Sector を活用すれば、AIワークロードの実行や機密性の高い業務の管理を、すべて自国の領域内で完結できます。このソリューションは、国内で最もセキュアなデータセンターへのオンプレミス導入を前提に設計された、スケーラブルで高性能なインフラです。
詳細はこちら → 政府および公共部門向け
公共部門向け
数分ではなく、数秒で動くAIエージェント
スピードとレイテンシはAIの価値を左右します。 SambaNovaは、独自のRDUを搭載し、最高性能の大規模オープンソースモデルにおいても高速な推論を実現します。
最大規模モデルで最高のパフォーマンスを実現
AIモデルはますます高度化、大規模化しています。 SambaNovaは、DeepSeekやLlamaをはじめとする最大級のモデルを、フル精度かつ開発者に必要なすべての機能を備えた形で実行可能です。

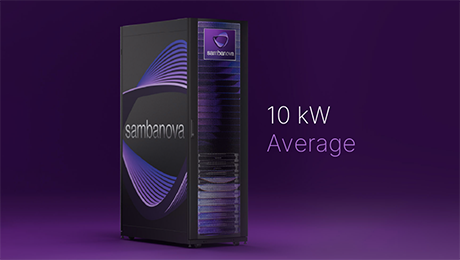
1kWhあたり、最も多くのトークンを生成
最高効率を誇るラックにより、1ワットあたりのトークン生成数を最大化します。



DeepSeek
DeepSeek-R1(6710億パラメータ)を含む先進的なDeepSeekモデルに対応。 コーディング・推論・数学で高性能を発揮し、他モデルの数分の一のコストで利用可能。
SambaNovaのRDU上で毎秒最大200トークンの高速推論を実現(Artificial Analysis社調べ)。

Llama
MetaのLlama 4シリーズのローンチパートナーとして、SambaNovaはオープンソースAIの最前線をリードしています。
Llama 3.1の全モデル(8B、70B、405B)にいち早く対応し、高速推論を実現した最初のプラットフォームです。
現在Meta社と連携し、ScoutおよびMaverickモデルでの高速推論提供に取り組んでいます。

OpenAI
OpenAIのWhisperモデルは、SambaNovaのRDU上でサポートされており、音声系AIアプリケーションの中核を担う存在となっています。 高速処理が可能なSambaNovaプラットフォームを活用することで、開発者は音声AIエージェントにおける新たなユースケースを実現し、より没入感のある体験を創出できます。

Introducing SambaManaged: A Turnkey Path to AI for Data Centers

OpenRouter uses SambaNova Cloud to deliver high speed LLM performance

SambaNova、AIプラットフォームをAWS Marketplaceで提供開始

SambaNova 2.0: Build with Relentless Intelligence
Introducing SambaManaged: A Turnkey Path to AI for Data Centers

DeepSeek R1-0528 is Live on SambaNova Cloud

Introducing Whisper Large-V3 to SambaNova Cloud

Qwen3 Is Here - Now Live on SambaNova Cloud

Meta Llama 4 Maverick & Llama 4 Scout on SambaNova Cloud

LLM-Judge for Multilingual Document Question Answering

The Only Inference Provider with High Speed Support for the Largest Models
