In the fast-paced world of LLM inference, there's been a growing buzz around achieving high tokens per second speeds. However, when it comes to critical enterprise applications, is tokens per second the only metric that matters? At SambaNova, we believe that first token time is equally, if not more, crucial for the complex, document-heavy and agentic use cases that businesses rely on.
In this blog post, we'll explore why tokens per second doesn't paint the full picture of enterprise LLM inference performance. We'll examine the limitations of focusing solely on this metric and why first token time is vital for enterprise use cases involving document intelligence, long documents, multiple documents, search, and function calling/agentic use cases. We'll also discuss how some solutions in the market fall short in addressing these challenges and how SambaNova's approach is uniquely tailored to meet the needs of the enterprise.
The Hype and Limitations of Tokens per Second
The pursuit of high tokens per second has led some AI systems vendors to cache model weights on SRAM and use hundreds of chips in their inference systems. While this approach can indeed achieve impressive decoding speeds, it comes with significant drawbacks:
- Slower first token generation due to low utilization across chips
- Difficulties handling longer input lengths common in enterprise use cases
- Limitations on model size and batch size due to SRAM constraints
In real-world scenarios, these SRAM-based inference engines can take over 1.4 seconds to generate the first token for a 3K token input (see table at the end), which makes the first token latency 85% of total inference time. For enterprises dealing with document intelligence, search, retrieval, and retrieval augmented generation, that's simply not fast enough.
The Importance of First Token Time in Enterprise Use Cases
Enterprise LLM inference applications often involve complex document-related tasks, such as:
- Processing long documents
- RAG over multiple documents
- Customer service assistant
- Utilizing function calling/ agentic applications
In these scenarios, the time it takes to generate the first token is critical. Enterprise applications can't afford to wait for that crucial first token, no matter how fast the subsequent tokens are generated.
For example, in chatbot applications, multi-turn conversations require including previous conversation history in the input prompt, often pushing the prompt length close to the maximum supported by the model. Similarly, in question-answering engines, retrieval augmented generation is used to avoid model hallucination, necessitating the retrieval and inclusion of top-k relevant articles in the prompt. Again, this results in prompt lengths approaching the model's maximum sequence length.
According to the Artificial Analysis report, it is clear that the "fast" token per sec solution does not equate the lowest latency and response time with the medium long length test case (1000 input tokens and 100 output tokens).


The SambaNova Solution: Designed for Enterprise Needs
At SambaNova, we've taken a different approach to address the unique challenges of enterprise LLM inference. Our RDU system employs a three tier memory system (520MB SRAM, 64GB HBM and 768GB DDR per socket) that allow reconfigurable dataflow to perform at its best with tensor parallelism to achieve high generation speeds – up to 450 tokens/s on 8 chips – while maintaining fast first token times of around 0.2 seconds. The extensive SRAM capacity facilitates the implementation of aggressive kernel fusion and graph looping within the dataflow micro-architecture, effectively minimizing end-to-end overhead. HBM plays a crucial role in supporting memory-intensive operations within cache graphs, particularly for token generation. Additionally, DDR memory is essential for handling extended sentence lengths, larger model sizes and Composition of Experts (CoE) for optimal statistical performance.
Our architecture is purpose-built to handle the long input lengths and complex use cases that enterprises demand. By avoiding the pitfalls of SRAM-only designs, such as the need for 8-bit weight quantization and additional chips for KV cache when increasing batch size, SambaNova solution delivers the best-in-class inference performance across a wide range of input token length that mission-critical enterprise applications require.
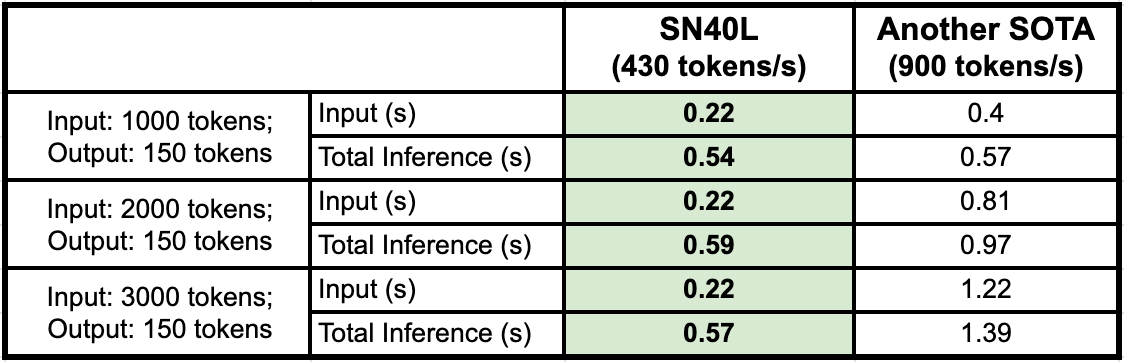
Table - Input process time and total inference time (llama 3 8B)

Figure - Total Inference time vs. input tokens (llama 3 8B)
The Conclusion
When it comes to enterprise LLM inference, focusing solely on tokens per second doesn't tell the whole story. First token time is a critical factor for the complex, document-heavy use cases that businesses rely on.
At SambaNova, we've built our solution from the ground up to meet the unique needs of the enterprise. Our 3-tier memory plus reconfigurable dataflow enable an efficient tensor parallelism approach that delivers the fast first token times and end-to-end performance that truly matter. For critical enterprise applications, SambaNova is the clear choice, providing the speed, flexibility, and scalability needed to succeed in a rapidly evolving landscape.