*A twitter user said that CausalLM-34b-beta is suspected to have MMLU contamination. On further investigation we do see the model is no longer available on Hugging Face. We are actively looking into this. In the spirit of transparency, we want to add this disclaimer until we understand more.
Note - this model is only used in v0.3 and thus v0.2 claims still hold true
Samba-CoE-v0.3, our latest Composition of Experts, surpasses DBRX Instruct 132B and Grok-1 314B on the OpenLLM Leaderboard. Samba-CoE-v0.3 is now available here on the Lepton AI playground.
Samba-CoE-v0.3 builds on a methodology used in releases v0.1 and v0.2 and improves the quality of the router and experts used in the composition. In v0.1 and v0.2 an embedding router was used to route to five experts based on the input query.
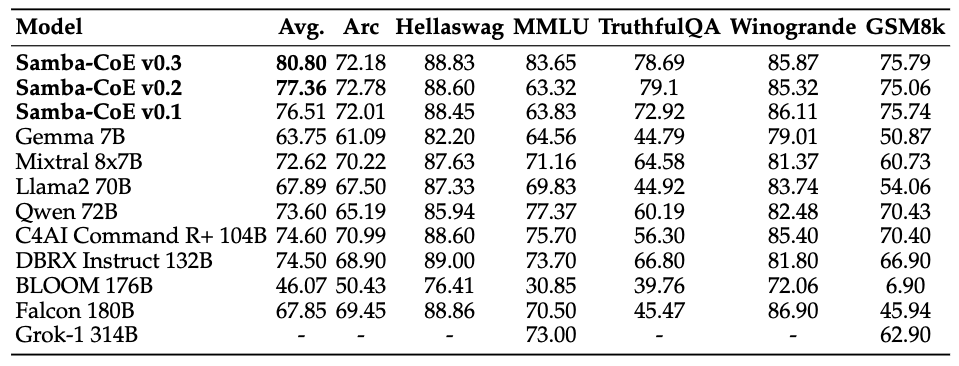
Figure 1. Samba-CoE v0.3 improves upon our previous versions and beats a number of similarly sized models as well as larger ones like DBRX Instruct 132B. Metrics presented are a best-of-16. Evaluation results for various models. All evaluations are done with llm-eval-harness similar to OpenLLM leaderboard. SambaCoE is a compound AI system with multiple open source models. SambaCoE v0.1, v0.2, and v0.3 models use a 7B embedding model to route the request to the relevant expert. SambaCoE v0.1 and v0.2 is a composition of five 7B experts, only one of which is active during inference. Samba v0.3 has four 7B experts and one 34B expert, of which only one is active during inference.
Samba-CoE-v0.3 improves the quality of the router by adding uncertainty quantification, which allows a query to be routed to a strong base LLM when the router confidence is low. This model demonstrates one example of how to build a competitive LLM system through composing multiple small experts on the SambaNova Platform.
Introduction to Composition of Experts
A Composition of Experts (CoE) refers to a novel and robust approach towards merging existing expert models together to create a unified user experience when interacting with them. This can be achieved via a variety of well studied methods - model merging, query routing, contrastive decoding, etc. If the experts are properly composed, this effectively creates a single large model consisting of multiple smaller models, which are adaptable, efficient, and capable of precise problem-solving across a broad range of domains and tasks.
Samba-CoE-v0.3 is a demonstration of this capability. It uses the query routing approach for composition. In this case, a task routing expert works with a set of task experts collectively. When a user inputs a query, the routing expert first determines the appropriate task expert to use. If the routing expert is unsure about what query is best suited for that expert, it will fall back to the base LLM that is part of the composition. This ensures that all types of queries are catered well, leading to a perception of a “single monolithic model”. Figure 2 best captures our approach
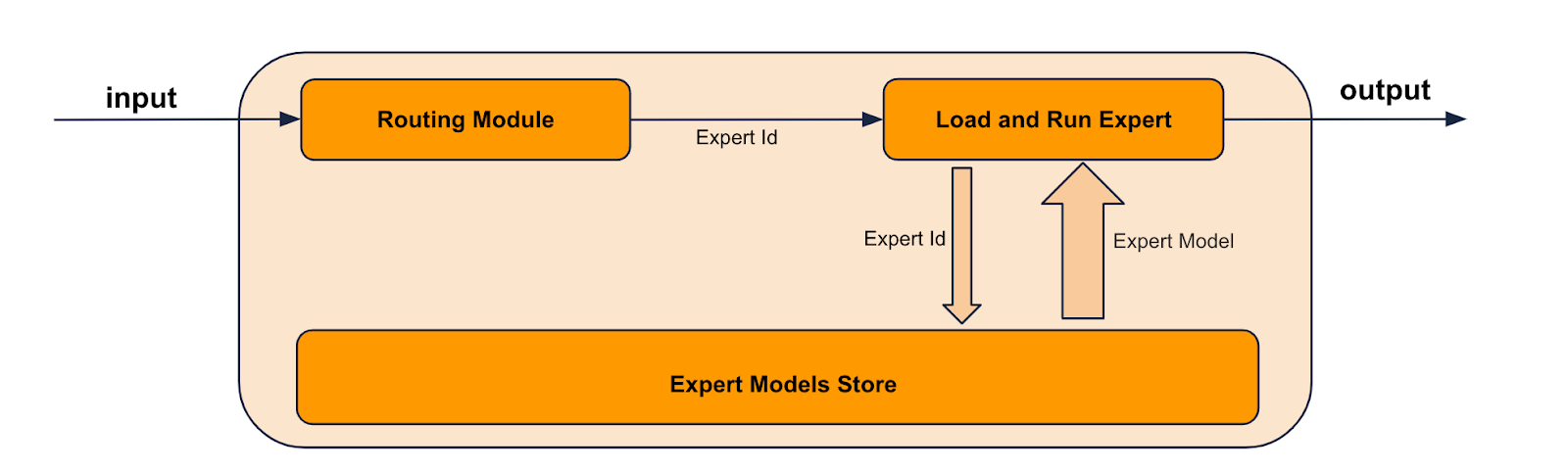
Figure 2. Samba-CoE v0.3, a query routing approach demonstration of a Composition of Experts enabled through the SambaNova Platform.
Expert Selection
We looked at derivatives of mistral-7b models, which have proven to have high performance, to understand their expertise across a wide variety of domains and benchmarks. Based on this analysis, we selected the following models to be part of our expert composition:
- vlolet/vlolet_merged_dpo_7B
- ignos/Mistral-T5-7B-v1
- macadeliccc/WestLake-7B-v2-laser-truthy-dpo
- yleo/EmertonMonarch-7B
If a query is not associated with the expertise of any of the above models, then there needs to be a fall back model that the query gets routed too. For this, we used the following model:
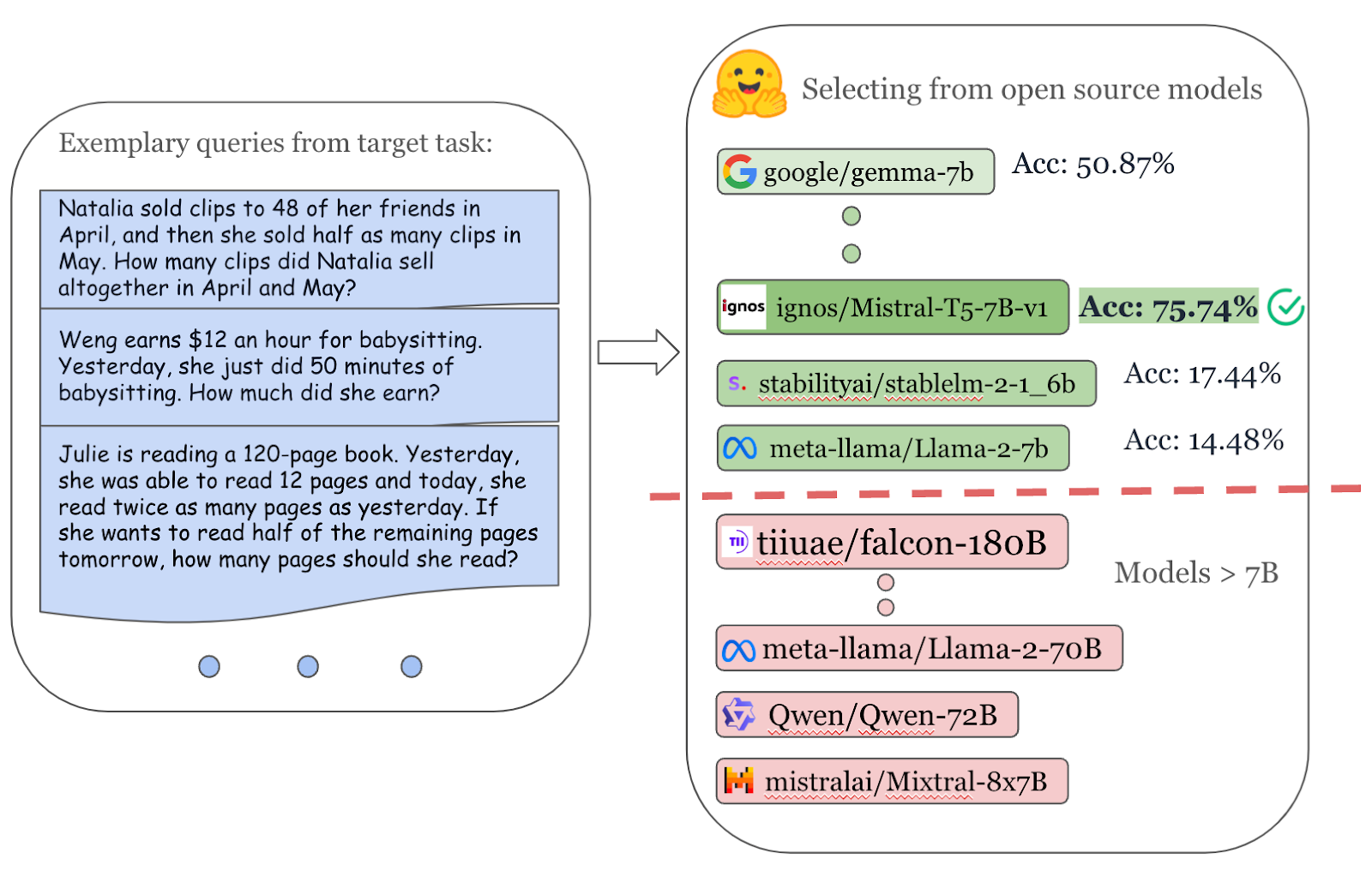
Figure 3. For this version we chose the highest quality 7b experts on a set of queries across various benchmarks and across multiple domains. In this figure we show how we selected ignos/Mistral-T5-7B-v1.
Router Construction
For the router, we leveraged a text embedding model intfloat/e5-mistral-7b-instruct, as it is one of the top performing models on the MTEB benchmark. Turning an embedding model into a query router requires the creation of unique text clusters that identify the expertise of each model. To do so, we curated queries from training splits of various benchmarks that the experts performed well on to create the embeddings. These embeddings naturally cluster and each cluster was assigned an expert label depending on their performance on the cluster. We then train a k-NN classifier using these embeddings and assigned expert labels. The validation split was used to determine the optimal ‘k’.
As discussed earlier, the Samba-CoEv0.3 router has a notion of router confidence measured via uncertainty quantification. This allows for optimal expert detection while reliably handling the out of distribution queries as well as labeling noise in the router training data. The uncertainty is measured in terms of entropy of the k-NN classifier prediction probabilities. For this, an uncertainty threshold ‘T’ is required and when the measured uncertainty on a given input is above ’T’, the input is routed to the base expert. Thresholding based on entropy leads to routers' decisions being overridden and this adversely affects the detection of the correct expert for a given prompt. Therefore, the threshold ‘T’ was chosen using the validation set such that it minimally affects the ‘probability of detecting’ the correct expert of the k-NN classifier.
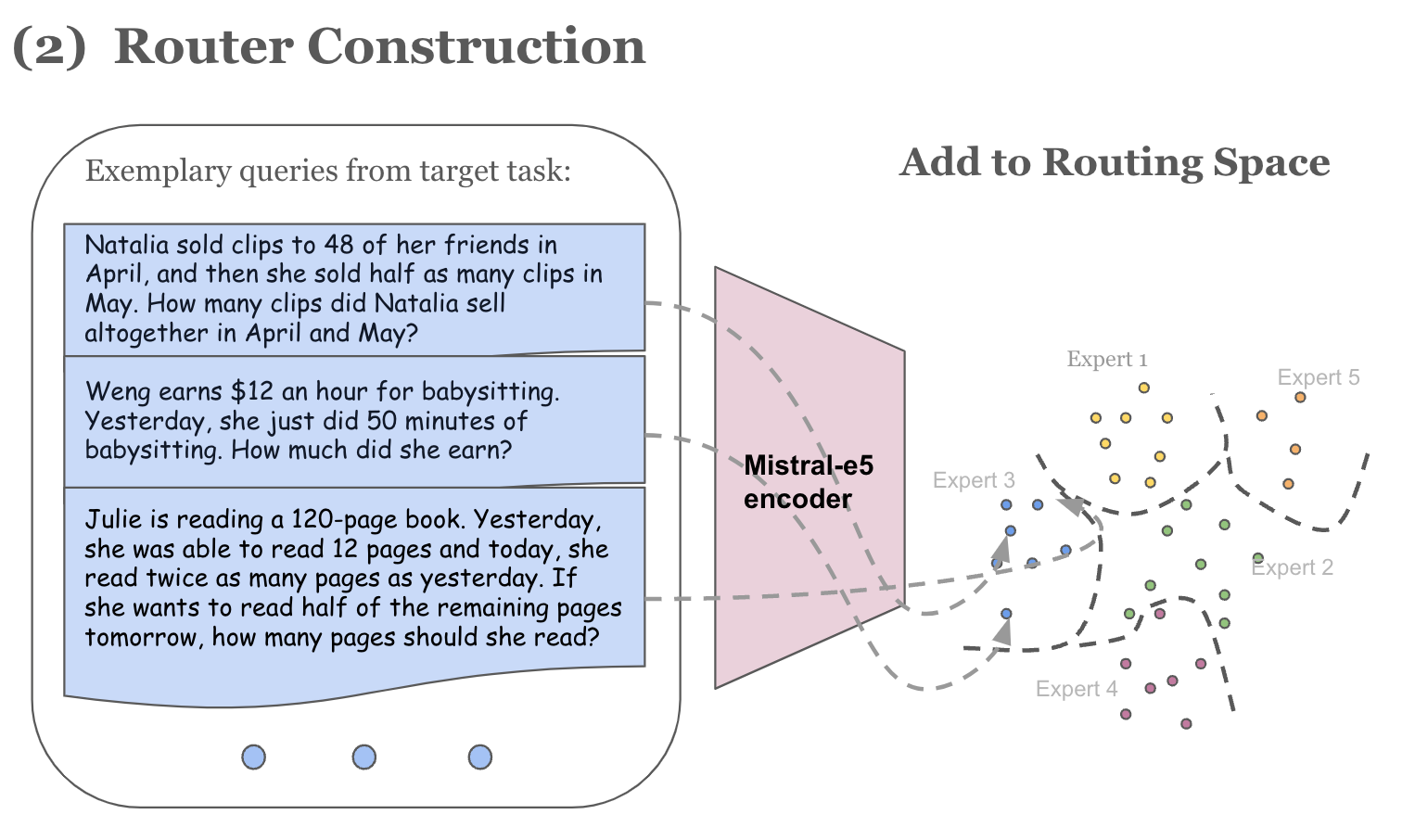
Figure 4: Router is created by embedding queries into a routing space and training a k-NN classifier to identify the closest expert cluster center of a new query.
Online Inference
At inference time, first the prompt embedding is obtained via e5-mistral-7b-instruct and then the trained k-NN classifier uses the prompt embedding to predict the expert label. The k-NN classifier prediction probabilities are used to compute the entropy for router uncertainty. If the entropy is below the threshold ‘T’ the prompt is routed to the predicted expert, otherwise the prompt is routed to the base expert.
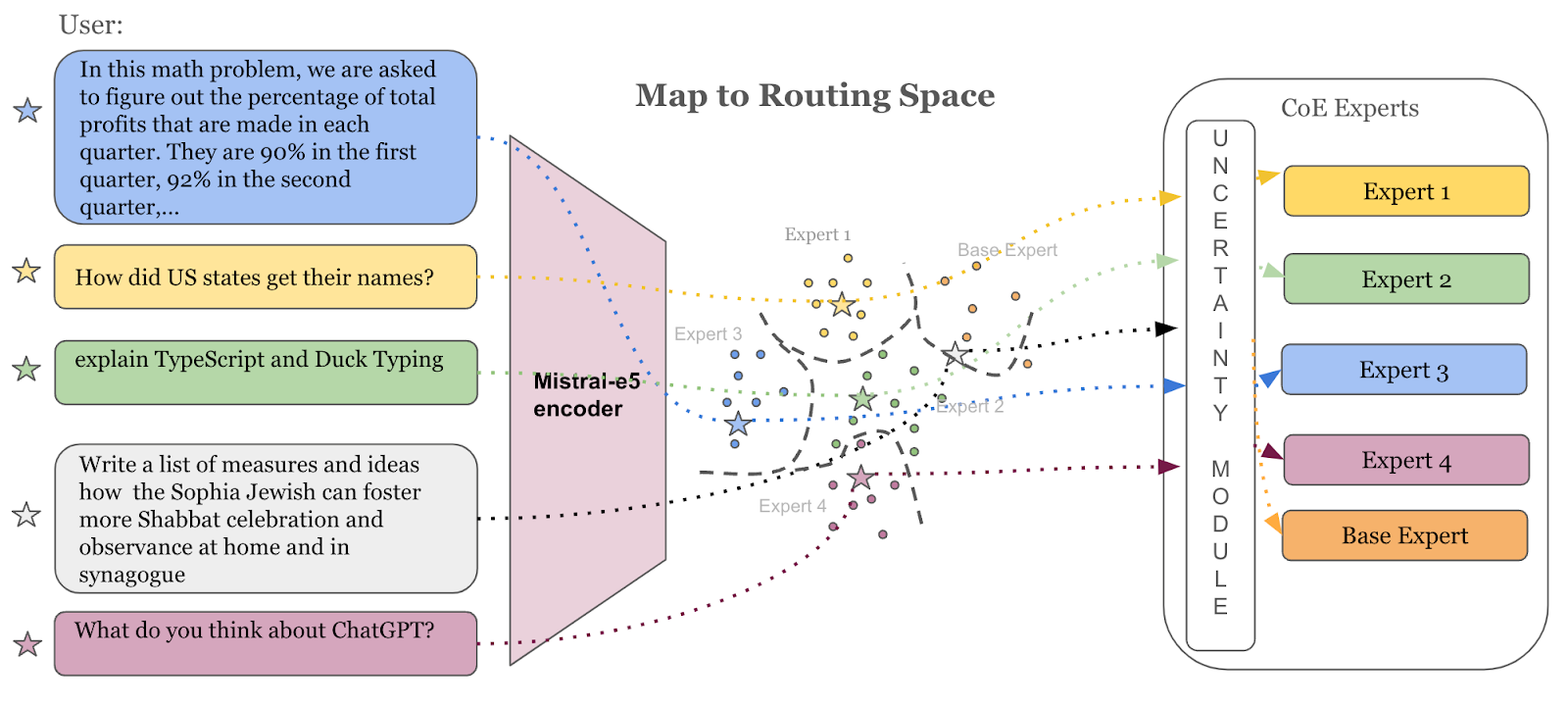
Figure 5: At inference time, the router identifies the appropriate expert for the query and uses the uncertainty threshold to determine router confidence. The gray query lies on the boundary between Expert 2 and the Base Expert and after uncertainty thresholding is routed to the Base Expert.
Evaluation
We evaluate the resultant system on various benchmarks in the OpenLLM leaderboard using llm-eval-harness with a best-of-16 - Arc, HellaSwag, MMLU, TruthfulQA, Winogrande and GSM8K. We ensure that there is no leakage of the testing data while determining the clusters used for the router.
Limitations
While Samba-CoE-v0.3 represents a significant advancement in AI technology, it has a few limitations that users should be aware of:
- Multi-turn Conversations: In Samba-CoE-v0.3, the router is trained using single-turn conversations only. As a result, the overall experience during multi-turn interactions may be suboptimal, as the router's decisions are based on the current message rather than the entire conversation history. This limitation might lead to inconsistencies or lack of coherence in the model's responses across multiple turns.
- Limited Number of Experts: The composition of experts in this release is limited, which may restrict the model's ability to handle a wide range of domain-specific tasks and queries.
- Absence of Coding Expert: Samba-CoE-v0.3 does not include a dedicated coding expert, which may limit its performance in generating accurate and efficient code snippets or assisting with programming-related tasks.
- Monolingual Support: The model is currently trained and optimized for a single language, which may hinder its usability for multilingual users or those requiring cross-lingual capabilities.
- Calibration for Chat Experience and Prompt Diversity: Samba-CoE-v0.3 may require further calibration to enhance its chat experience and ability to handle a diverse range of prompts, as the current version may not consistently provide engaging and contextually relevant responses.
Despite these limitations, the Samba-CoE-v0.3 model demonstrates significant potential for AI-driven solutions and lays the groundwork for future improvements and expansions in the realm of Composition of Experts architectures.
Acknowledgements
We would like to express our sincere gratitude to the creators of the open-source models that were used as experts in the composition of Samba-CoE-v0.3. These models include Mistral-7b, vlolet/vlolet_merged_dpo_7B, ignos/Mistral-T5-7B-v1, macadeliccc/WestLake-7B-v2-laser-truthy-dpo, yleo/EmertonMonarch-7B, dranger003/CausalLM-34b-beta-iMat.GGUF. Their contributions were essential to the success of our Composition of Experts approach. We also extend our appreciation to the intfloat/e5-mistral-7b-instruct embedding model, which served as the foundation for our router.
We are grateful to the developers and maintainers of the OpenLLM leaderboard benchmarks, including Arc, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. These benchmarks were important in evaluating the performance of Samba-CoE-v0.3.
We would also like to thank Hugging Face and the entire open-source community for their continuous contributions of better models. SambaNova is committed to supporting and contributing back to the community. We believe that the collaborative efforts of the AI community are crucial for driving innovation and advancing the field of artificial intelligence.