As enterprises move to adopt generative AI at scale, it is critical that they choose the best infrastructure to support this next step in their digital transformation. Utilizing the right infrastructure can minimize costs, increase efficiency, accelerate their adoption of this transformative technology, and deliver a significantly better TCO.
While choosing the right technology to power generative AI infrastructure is critical, differentiating between disparate technologies can be daunting. The purpose of this blog is to enable organizations to more easily make an informed decision between competing technologies.
Comparing the SambaNova RDA to GPUs
As the first full stack platform purpose built for generative AI, people frequently compare SambaNova to Nvidia. In particular, comparing SambaNova’s latest chip, the SN40L, to the Nvidia H100. At a high level, this is an apples to oranges comparison. SambaNova does not offer individual chips for sale but instead deploys a complete, purpose built platform that includes hardware, networking, software, and models, thereby eliminating the need to learn proprietary languages, such as CUDA. Nvidia does sell their chips individually or as part of a system, but only SambaNova offers the first, full stack platform, from chips to pre-trained models, purpose built for generative AI. These are two very different solutions, which is one of the reasons that SambaNova delivers a TCO several times better than Nvidia.
When comparing the SN40L and the Nvidia H100, there are two fundamental differences that must be considered: architecture and memory.
Architecture
The first is the base architecture of these chips. GPUs and CPUs use an architecture known as an instruction set architecture (ISA). This is the way that CPUs were originally designed. GPUs, which were originally created to power computer graphics and were only later repurposed for AI, utilize the same basic architecture with some key differences. To dramatically oversimplify, CPUs have a few very large cores and are best for general purpose computing and performing a number of different tasks. GPUs have many smaller cores, sometimes thousands, and are best for handling multiple, similar processes that can be done in parallel. Ultimately, this difference is why CPUs are better at model inference and GPUs are better suited for model training.
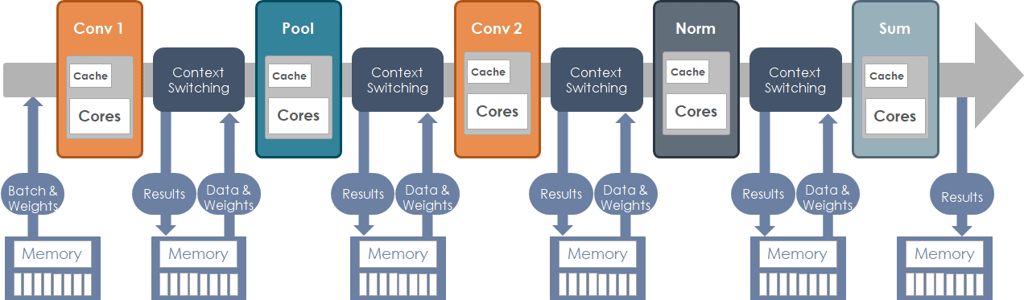
Deep learning is inherently a dataflow-oriented workload. Since GPUs utilize an instruction set architecture, they perform a kernel-by-kernel programming model. In effect, this means that they use a very compute and memory intensive process. Consider the following simple, logical compute graph for a convolution network with just five kernels.

Handing this process on a traditional core-based architecture requires that each kernel must be individually loaded onto the CPU or GPU, data and weights are then read from system memory onto the processor, calculations are performed, and the outputs are then written back to system memory. This process is then repeated for each successive kernel. Clearly, this results in an excessive volume of data movement and consumes a large amount of memory bandwidth, resulting in extremely poor hardware utilization.
In comparison, the SambaNova Reconfigurable Dataflow Architecture (RDA) creates custom processing pipelines that allow data to flow through the complete computation graph. This minimizes data movement and results in extremely high hardware utilization.
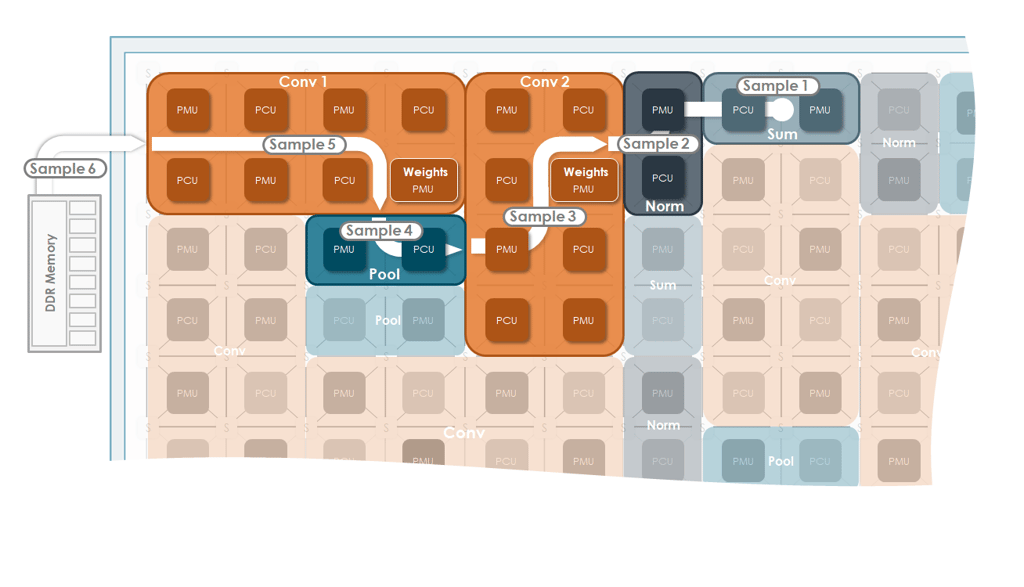
The SambaNova software provides dataflow patterns as needed for each kernel’s unique requirements. Spatial programming is used to ensure that the layout of the operation minimizes data movement to achieve high efficiency.
For more detailed information on how the ISA-based architecture compares to the RDA, read this whitepaper.
This is the difference between being purpose built for generative AI compared to simply being a legacy technology that has been repurposed. Naturally, this fundamental difference in architecture makes comparisons such as processor speed, number of cores, and other metrics commonly applied to CPUs and GPUs inapplicable.
Memory
It may seem obvious, but it needs to be said that as LLMs continue to get bigger, they will take up more space in memory. This is important to this discussion because when an AI model is given a prompt, the entire model is loaded into on-chip memory. All possible results are calculated, and then the model determines the most correct response and returns that as the result. The model is then written from on-chip memory back to system memory. This process happens every time that a prompt is given to the AI model.
To be able to process this requires that either the processor being used have sufficient memory to hold the entire model or be configured in such a way that the model is broken into parts and then spread across however many processors are needed to run the model. Clearly, if the model is being spread across multiple nodes, then there is configuration and management overhead required to parallelize the nodes, manage the model, and so forth.
Given that models have now reached a trillion parameters in size and are continuing to grow rapidly, this presents a major hurdle to GPUs. Nvidia GPUs, such as the A100 and H100, have 80GB of on-chip memory, which is only a small fraction of what is required for modern generative AI models. As a result, running these models on Nvidia GPUs can require a huge number of systems, along with all the associated costs and overhead. While this may be great for Nvidia’s bottomline, it can be a massive expense and technical challenge for the end customer.
In contrast, the SambaNova SN40L has a three tiered memory architecture, specifically designed for the largest generative AI models. The SN40L has terabytes of addressable memory and can easily run trillion parameter models on a single SambaNova Suite node.
As discussed above, SambaNova and Nvidia offer very different products and drawing direct comparisons between them can be difficult. It is more than the fact that SambaNova delivers the first complete, full stack solution purpose built for generative AI, that can be installed on-premises and running in minutes or deployed as-a-Service immediately, where Nvidia provides parts of the stack and which can require a great deal of time, effort, and expense required to make it work. Architecturally, the SambaNova platform was purpose built to power the largest generative AI models of today and tomorrow, while Nvidia uses a legacy architecture that was built for a different purpose.
Enterprise organizations need to take advantage of generative AI to accelerate their digital transformation. Doing so at scale requires the largest, multi-trillion parameter models, and running them efficiently requires a platform specifically designed to power those models.
To learn more about SambaNova, click here.