We're thrilled to unveil Samba-CoE-v0.1, a scaled down version of Samba-1, our latest breakthrough model that leverages the Composition of Experts (CoE) methodology. Samba-CoE-v0.1 demonstrates the power of CoE and the sophisticated routing techniques that tie the experts together into a single model. By ensembling existing open source models using this methodology, we are able to surpass Mixtral 8x7B by 3.29 percentage points, Gemma-7B by 12 percentage points, Llama2-70b by 8 percentage points, Qwen-72B by 2 percentage points and Falcon-180B by 8 percentage points across various benchmarks. The model also achieves a win-rate of 75% against GPT-3.5-turbo using GPT-4 as-a-judge. Samba-CoE-v0.1 achieves this remarkable feat at the inference cost equivalent to two calls to 7 Billion parameter LLM models. The CoE approach represents an innovative and a more scalable method for constructing cutting-edge Large Language Models (LLMs) at just a fraction of the cost—approximately 1/10th—of their larger counterparts in a modular fashion.
Try out the model for yourself at this Hugging face Space!
If you are excited about this work and want to discuss with SambaNova researchers on how to build on top, join our Discord channel.

Table 1. GPT4-Eval on 123 diverse curated queries sampled from MT-bench and UltraChat
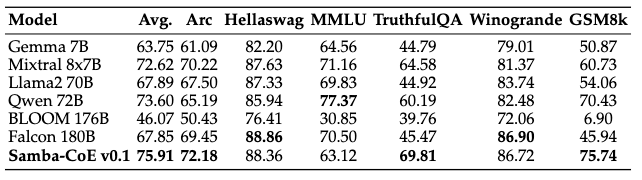
Table 2. Benchmark results for Samba-CoE-0.1 vs. Mixtral 8x7B, Qwen 72B, Falcon 180B.
CoE Methodology
The Composition of Experts (CoE) methodology proposes a novel and robust approach towards merging existing expert models together to create a unified experience to interact with them. This is achieved using a two step approach - identifying the experts and building a router. The experts step represent models that achieve remarkable accuracy on tasks that a user cares about. The router is responsible for understanding which expert is most suited for a particular query and routing the request to that expert. The router should be robust to variations of prompts, multi-turn, and other features one expects from a general purpose chatbot. If designed well, this effectively creates a single large model composed of multiple smaller models. A more figurative representation of this methodology can be found in Figure 1.
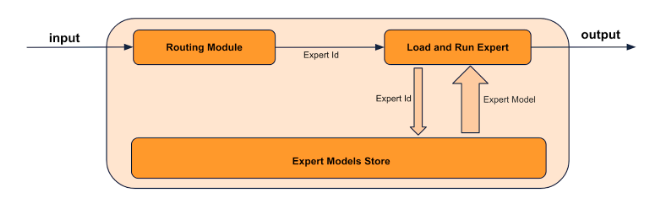
Figure 1. Composition of Experts (CoE) system diagram
Samba-CoE-v0.1 is a composition of five expert models and a router. The five experts that we use are ignos/Mistral-T5-7B-v1, cookinai/DountLM-v1, CultriX/NeuralTrix-7B-dpo, vlolet/vlolet_merged_dpo_7B, and macadeliccc/WestLake-7B-v2-laser-truthy-dpo. The ignos/Mistral-T5-7B-v1 model excels in mathematical tasks (GSM8K benchmark), cookinai/DountLM-v1 model is versatile across various domains (MMLU benchmark), CultriX/NeuralTrix-7B-dpo model prioritizes precision (TruthfulQA and Hellaswag benchmarks), while the vlolet/vlolet_merged_dpo_7B and macadeliccc/WestLake-7B-v2-laser-truthy-dpo models showcase their expertise in common sense reasoning, outperforming in the Arc Challenge and Winogrande benchmarks. The router leverages intfloat/e5-mistral-7b-instruct as the text embedding backbone and is trained to understand the nuances of the various expertise these models provide and route user queries robustly to these experts.
How can SN40L enable Composition of Experts at fraction of a cost?
Scaling the CoE methodology to a larger number of experts while maintaining service efficiency at lower cost, requires a system that can hold all the models in a region that can be accessed quickly. One way to achieve this is to hold all the experts in HBM or SRAM. However, on traditional accelerators, this can only be achieved by running multiple instances of the accelerator to create an effective fast memory region size that can hold all the experts. In traditional accelerators, the size of the fast memory is tied to compute units limiting its scalability capabilities.
However, the SambaNova SN40L's unique approach to memory system design is particularly well-suited for deploying such models. The SN40L has a three-tier memory architecture (as shown in Figure 2) that allows for efficient storage of experts and retrieving them when needed. The experts can live on SRAM, HBM or DDR and dedicated BW between them, without any host interference, which allows efficient swapping of experts without any switching cost. The size of the DDR Memory allows one to host a total of 5 Trillion parameters across multiple experts.
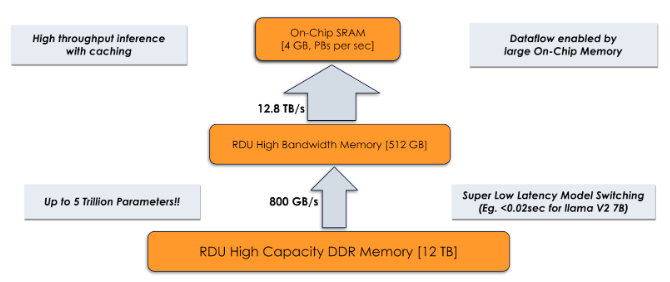
Figure 2: SN40L three tier memory architecture.