Today, we announced Samba-1, a Composition of Experts model with over 1 trillion parameters, built on top of open source models.
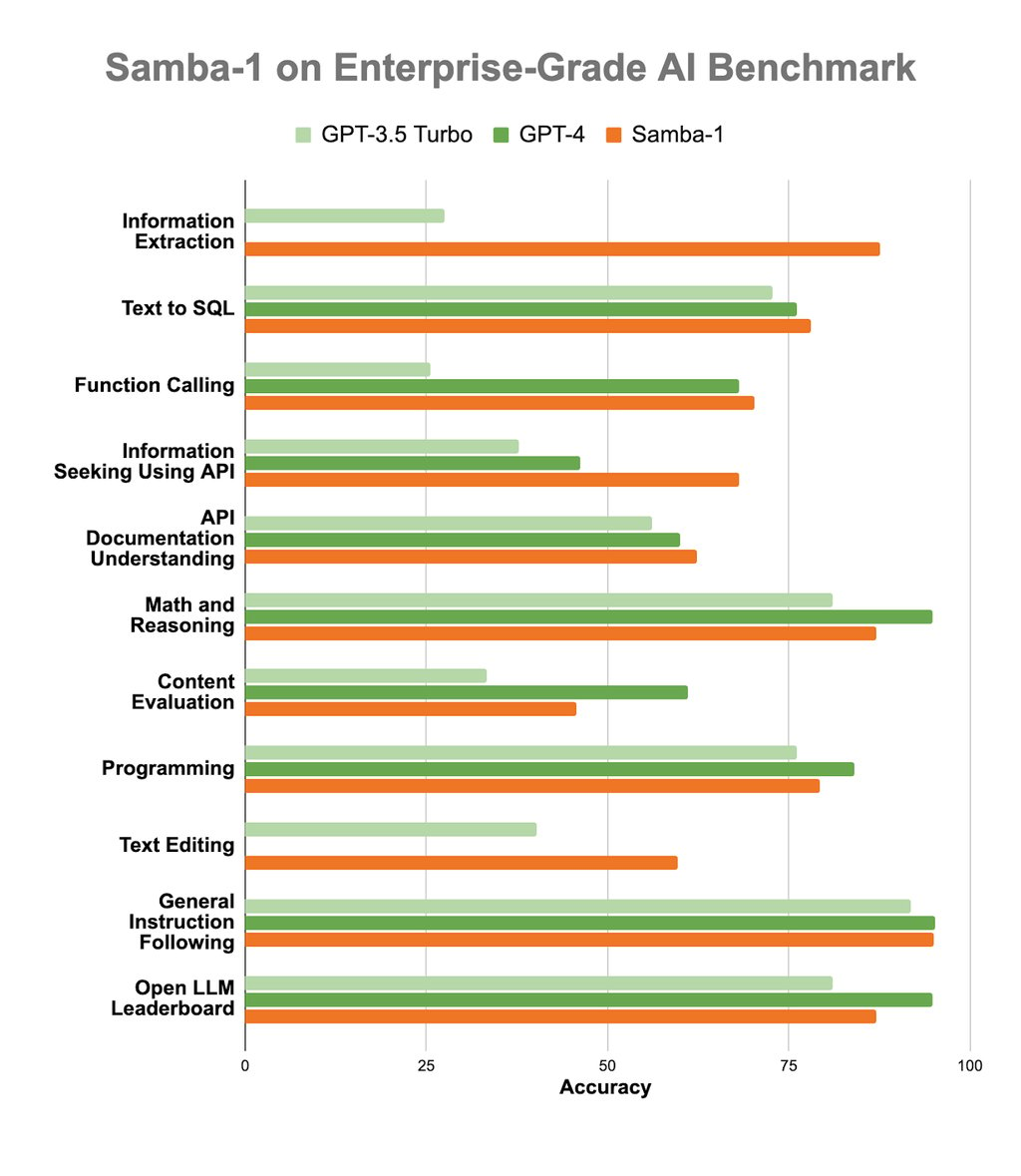
These parameters are made up of a collection of 50+ state-of-the-art expert models from the broader open source community and from SambaNova. By combining these expert models together, we are able to harness their combined power into a single Composition of Experts model that outperforms GPT-3.5 across all enterprise tasks, and outperforms or matches GPT-4 on a large subset of those tasks, but with a fraction of the compute footprint.
To demonstrate this, we would like to introduce the Enterprise Grade AI (EGAI) benchmark. The EGAI benchmark is a comprehensive collection of widely adapted benchmarks sourced from the open source community. Each benchmark is carefully selected to measure specific aspects of a model’s capability to perform tasks pertinent to enterprise applications and use cases.
Highlighting the experts
- Text to SQL expert - Sambacoder-nsql-Llama-2-70B is a model trained to predict the SQL query, given a text input. Built on top of Llama2, the model was pre-trained on SQL split of the stack dataset and further instruction-tuned on the NSText2SQL dataset by Number Station. This model outperforms GPT-4 on the spider benchmark. More details can be found at on the Hugging face Model Card - https://huggingface.co/sambanovasystems/SambaCoder-nsql-llama-2-70b
- Math and Reasoning Expert - Xwin-Math are a series of powerful models for math problems created by Xwin-LM: Xwin-Math-7B-V1.0, Xwin-Math-13B-V1.0, and Xwin-Math-70B-V1.0. These models are fine tuned on top of Llama-2 models. Xwin-Math-70B ranks 1st on pass@1 on the GSM8k benchmark and is competitive with GPT models. These models can be found in the HF page linked.
- Function Calling and API - Built on top of llama2-13B NexusRaven Flow is a new state of the art open source LLM for function calling. It matches GPT-3.5 in zero-shot for generic domains and beats it by 4% in security software. It outperforms GPT-4 by up to 30% with retrieval augmentation for software unseen during training. More details can be found here - https://huggingface.co/Nexusflow/NexusRaven-V2-13B
At the bottom of this page, you can find a full list of all benchmarks.
Bringing the composition together
But that's not all. Not only are we able to demonstrate the quality of these individual experts, but we combine them together behind a single endpoint, giving us the ability to dynamically route to one or more experts in a way that unlocks their combined power, making them work together as one single model behind a single user interface.
We also just open-sourced a scaled-down version of Samba-1, that demonstrates the power of expert models with a sophisticated router, outperforming state-of-the-art open source models, both traditional models and mixture of experts. This demonstrates that Composition of Experts is the best architecture for building state-of-the-art AI, as well as being the most cost effective and scalable.

Table 1. GPT4-Eval on 123 diverse curated queries sampled from MT-bench and UltraChat
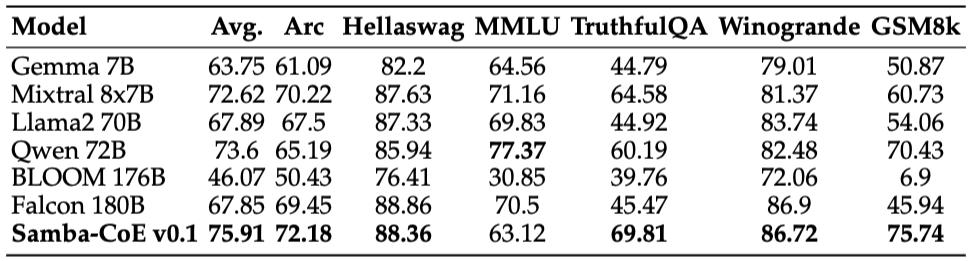
Table 2. Benchmark results for Samba-CoE-0.1 vs. Mixtral 8x7B, Qwen 72B, Falcon 180B.
We are just getting started. In the coming months, we will expand the experts available in Samba-1 to increase the breadth of tasks, diversity of experts per task, and improve upon our router to push the state-of-the-art forward and show that a Composition of Experts is the model architecture for Enterprise AI.
You can try Samba-1 now via trysambanova.ai
You can try Samba-CoE v0.1 in our Hugging face Space
Comprehensive Benchmarks
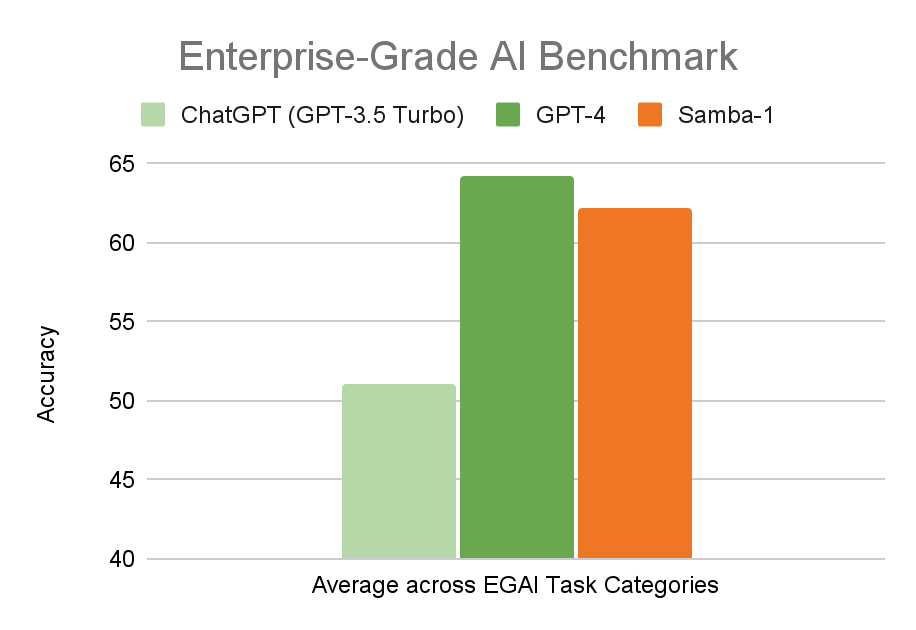
The average scores are calculated across a combination of 36 different benchmarks measured by accuracy. These metrics utilize publicly accessible data from both GPT-3.5 turbo and GPT-4. These benchmarks include GSM8K, Arc, Winogrande, TruthfulQA, MMLU, Hellaswag, ApacaEval, HumanEval, MBPP, Summarization Judge, Code Judge, Climate, Stack, OTX, VT_multi, NVDLibrary Multi, Spider, and more.
| Benchmark Name | Benchmark Details | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| General | ACE05 | UniNER-7B-all | 27.6 | - | 87.6 |
| General | ACE04 | UniNER-7B-all | 27.7 | - | 87.5 |
| Biomed | bc5cdr | UniNER-7B-all | 53.4 | - | 91.4 |
| Biomed | bc4chemd | UniNER-7B-all | 36.5 | - | 89.8 |
| Biomed | JNLPBA | UniNER-7B-all | 16.6 | - | 76.6 |
| General | conllpp | UniNER-7B-all | 53.5 | - | 97 |
| General | Ontonotes | UniNER-7B-all | 30.7 | - | 89.1 |
| Biomed | GENIA | UniNER-7B-all | 42.6 | - | 80.6 |
| Biomed | ncbi | UniNER-7B-all | 43.1 | - | 88.1 |
| Clinical | i2b2 2010 concepts | UniNER-7B-all | 43.6 | - | 90.6 |
| Clinical | i2b2 2012 temporal | UniNER-7B-all | 29.5 | - | 82.9 |
| Clinical | i2b2 2014 deid | UniNER-7B-all | 16.5 | - | 92.2 |
| Clinical | i2b2 2006 deid 1B | UniNER-7B-all | 9.7 | - | 96.9 |
| Biomed | BioRED | UniNER-7B-all | 39.1 | - | 89.9 |
| Biomed | AnatEM | UniNER-7B-all | 26.1 | - | 89.9 |
| Social | WikiANN | UniNER-7B-all | 53 | - | 86.3 |
| Social | WikiNeural | UniNER-7B-all | 58.7 | - | 94.6 |
| Program | MultiNERD | UniNER-7B-all | 59.1 | - | 94.5 |
| Program | SOFC | UniNER-7B-all | 40.4 | - | 84.1 |
| STEM | SciERC | UniNER-7B-all | 13.3 | - | 67 |
| STEM | SciREX | UniNER-7B-all | 16.7 | - | 70.5 |
| Law | MAPA-en-fine | UniNER-7B-all | 17.4 | - | 86.4 |
| Law | MAPA-en-coarse | UniNER-7B-all | 29 | - | 76.1 |
| Law | E-NER | UniNER-7B-all | 15.4 | - | 94.4 |
| STEM | CrossNER science | UniNER-7B-all | 68 | - | 70.8 |
| Social | CrossNER politics | UniNER-7B-all | 69.5 | - | 67.3 |
| Program | CrossNER AI | UniNER-7B-all | 53.4 | - | 63.6 |
| STEM | DEAL | UniNER-7B-all | 27.6 | - | 79 |
| Program | Stackoverflow-NER | UniNER-7B-all | 11.6 | - | 65 |
| STEM | SoMeSci | UniNER-7B-all | 2.1 | - | 81.1 |
| Clinical | HarveyNER | UniNER-7B-all | 12.6 | - | 73.7 |
| Social | FabNER | UniNER-7B-all | 16.3 | - | 82.2 |
| Transport | FindVehicle | UniNER-7B-all | 11.5 | - | 99.1 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| Climate | Nexusflow/NexusRaven-V2-13B | 25.53 | 68.09 | 70.21 |
| Stack | Nexusflow/NexusRaven-V2-13B | 44.95 | 48.14 | 59.90 |
| Places | Nexusflow/NexusRaven-V2-13B | 25.00 | 43.75 | 50.00 |
| OTX | Nexusflow/NexusRaven-V2-13B | 89.13 | 90.22 | 90.22 |
| VirusTotal | Nexusflow/NexusRaven-V2-13B | 81.00 | 88.00 | 80.13 |
| VT_Multi | Nexusflow/NexusRaven-V2-13B | 2.04 | 36.73 | 38.78 |
| NVDLibrary Single | Nexusflow/NexusRaven-V2-13B | 48.00 | 77.00 | 66.67 |
| NVDLibrary Multi | Nexusflow/NexusRaven-V2-13B | 7.14 | 7.14 | 25.00 |
| VT_Multi Parallel | Nexusflow/NexusRaven-V2-13B | 14.29 | 28.57 | 42.86 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| Information Retrieval | Nexusflow/NexusRaven-V2-13B | 37.78 | 46.22 | 68.22 |
| Application Manipulation | Nexusflow/NexusRaven-V2-13B | 46.00 | 42.89 | 47.33 |
| Financial Transaction Processing | Nexusflow/NexusRaven-V2-13B | 34.22 | 44.89 | 53.11 |
| Real-Time Search | Nexusflow/NexusRaven-V2-13B | 40.89 | 51.11 | 52.67 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| Tool Selection | Nexusflow/NexusRaven-V2-13B | 56.19 | 60 | 62.38 |
| Parameter Identification | Nexusflow/NexusRaven-V2-13B | 24.29 | 32.86 | 37.62 |
| Content Filling | Nexusflow/NexusRaven-V2-13B | 16.19 | 25.24 | 30 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
|
GSM8k |
81.0 |
94.8 |
87.0 |
| Benchmark Name | Benchmark Details | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| Summarization Judge | Agreement Rates | Auto-J | 33.3 | 61.1 | 45.8 |
| Examination Judge | Agreement Rates | Auto-J | 40.3 | 51.4 | 38.9 |
| Code Judge | Agreement Rates | Auto-J | 36.7 | 68.3 | 47.5 |
| Rewriting Judge | Agreement Rates | Auto-J | 32.5 | 58.3 | 49.2 |
| Creative Writing Judge | Agreement Rates | Auto-J | 48.2 | 65.3 | 59.7 |
| Functional Writing Judge | Agreement Rates | Auto-J | 40.4 | 67.9 | 61.7 |
| General Communication Judge | Agreement Rates | Auto-J | 47.6 | 52.4 | 55.2 |
| Natural Language Processing Judge | Agreement Rates | Auto-J | 45.8 | 67.8 | 57.6 |
| Benchmark Name | Benchmark Details | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| Spider | Execution Accuracy | SambaCoder-nsql-llama-2-70b | 72.8 | 76.2 | 78.1 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| HumanEval Python | DeepSeekCoder-33B | 76.2 | 84.1 | 79.3 |
| HumanEval Multilingual | DeepSeekCoder-33B | 64.9 | 76.5 | 69.2 |
| MBPP | DeepSeekCoder-33B | 70.8 | 80 | 70 |
| Benchmark Name | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| EXPLORE-INSTRUCT-Brainstorm | Wanfq/Explore-LM-Ext-7B-Brainstorming | 40.29 | - | 59.71 |
| EXPLORE-INSTRUCT-Rewriting | Wanfq/Explore-LM-Ext-7B-Rewriting | 68.42 | - | 31.58 |
| Benchmark Name | Benchmark Details | Samba-1-Expert | GPT-3.5 Turbo | GPT-4 | Samba-1 |
| GSM8k | Accuracy | Xwin-Math-70B-V1.0 | 81 | 94.8 | 87 |
| Arc | Accuracy | tulu-2 | 85.20 | 96.30 | 72.1 |
| Winogrande | Accuracy | tulu-2 | 81.60 | 87.50 | 83.27 |
| TruthfulQA | Accuracy | Lil-c3po | 57.50 | 59.00 | 68.73 |
| MMLU | Accuracy | tulu-2 | 70.00 | 86.40 | 69.84 |
| Hellaswag | Accuracy | tulu-2 | 85.50 | 95.30 | 88.99 |