In Part 1 of this two-part blog, we discussed the SambaNova product components, discussed some fault management concepts, and then circled back to the SambaNova Fault Management (SNFM) component. We discussed some basics, and then considered possible event sources in detail. Now we will dive more deeply into the architecture, starting with the architecture and then exploring error handling, fault diagnosis, and fault handling for different types of faults. Finally we will explore error and fault logging and then briefly consider APIs and tools.
SNFM ARCHITECTURE
SNFM interacts with other software components directly to receive different classes of events. The interfaces between components vary, and depend on the type of communication.
- The RDU driver is a kernel driver that manages each of the RDU devices. This software component manages asynchronous events that are delivered via interrupt, and forwards them to affected applications and to SNFM.
- The SambaNova daemon (SND) is responsible for coordinating a variety of operations on the devices, from initialization of software services and hardware systems to system configuration. SND reports events directly to SNFM.
SNFM runs as a privileged process in userspace, and consists of sub-modules that implement key pieces of functionality. It is an administrative task and as such runs under privileged user mode. SNFM can be run by any user to check system health status. Any updates to faults will require privileged user permission e.g. clearing a fault. SNFM sends information to both SND and the RDU driver to attempt recovery actions, and to adjust available resources when faults are present.
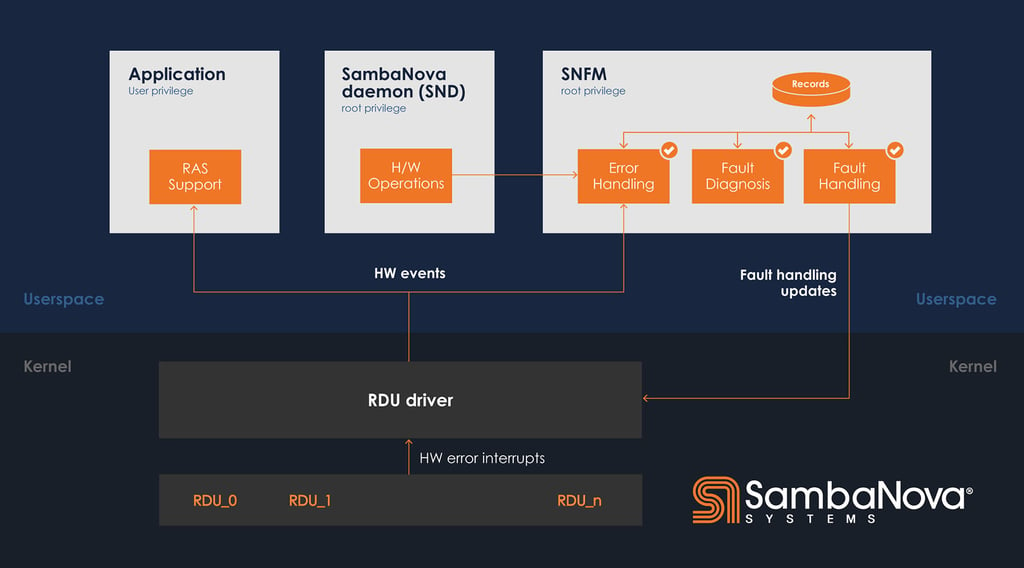
ERROR HANDLING (EH)
The Error Handling (EH) module is responsible for converting hardware error events into recorded error entries. As a part of this step, SNFM localizes the error to a specific component within a subsystem, and collects error-specific telemetry for recording purposes.
Each reported event has a set of event-specific information which specifies the affected component. The EH module takes this information and creates an error entry. This error entry contains an error type (e.g., uncorrectable memory error), error-specific information (e.g., affected address), and the affected component (e.g., memory module). Additionally, the error entry created in the EH module is persistent. When the user accesses the error history of the system, the history will contain all collected information from the EH module.
FAULT DIAGNOSIS (FD)
After an error entry is created by the EH module, the error entry is passed to the Fault Diagnosis (FD) module, which determines whether or not the error creates a new fault. This portion of SNFM applies the SNFM policy for the error type.
The policy for a specific error dictates the following:
- Threshold frequency: How frequently does the error need to occur to generate a fault?
- Criticality: How critical is this fault to overall system health?
- Produced fault type: What fault will be generated when the threshold frequency is met?
After applying the policy, SNFM creates a fault entry. The fault entry is associated with the specific component from the error entry, and a link is created between the new fault entry and the error entry that generated the fault. Additionally, SNFM updates the system inventory state to reflect the new fault. Certain classes of hardware error events do not result in faults and these end up getting reported in the error logs only. These types of errors are mostly software programming errors and hardware components are not faulted while handling these errors.
FAULT HANDLING (FH)
After receiving and logging events, except for no-fault events such as user errors, the events will be forwarded to the Fault Handling (FH) module. For specific faults, there are additional actions required to recover the system. The FH module is responsible for executing those actions. Based on the recovery classifications, the FH module will then perform a recovery action. These recovery classifications can be summarized as follows.
Recoverable Faults
Many classes of faults are recoverable. We consider a fault recoverable if its recovery mechanism results in a fully operational and healthy system. For these types of faults, the FH module usually triggers a hardware reset in order to clear the system state, which typically requires a targeted hardware reinitialization. Although fully automated, these recovery processes can take some time to complete; however, in a majority of cases, recovery is preferred over system power-on resets which can take longer. Thus, total downtime is greatly reduced.
Examples of recoverable faults include RDU SOC-level system hangs. There are a number of hardware-supported resets that will, in most cases, clear these hangs, bringing the system back to fully operational state.
Semi-Recoverable Faults
Several types of faults are considered to be semi-recoverable. This classification identifies faults that impact or degrade the system but do not result in further disruptions, such as initiating system power cycles. Usually, full recovery requires administrator intervention, but the system remains operational in the meantime.
In these cases, recovery is usually software-based rather than hardware-based. These recovery mechanisms tend to be more varied than those for recoverable faults, but they usually involve some form of system degradation that results in removing resources from the available pool for applications.
A prime example of semi-recoverable faults is faults that occur on memory subsystems. In some of these memory faults, the FH module programmatically removes impacted physical memory from the system and reconfigures the remaining memory. From the perspective of applications, only system capacity is impacted.
Non-Recoverable Faults
Some types of faults are non-recoverable. These are usually the most disruptive, at a minimum requiring system administrator intervention, and at worst requiring physical component replacement. Some non-recoverable faults can even trigger immediate system shutdowns in order to prevent damage to components.
An example of hardware failures that can lead to non-recoverable faults are physical connections such as in IO cables or physical memory slots becoming loose. Other examples are software-induced faults that render a typically-recoverable fault as unrecoverable. Lastly, the most catastrophic types of hardware failures such as overheated components result in immediate shutdown. In these cases system administrators have to manually repair connections, replace components, or power systems back on.
SYSTEM HEALTH MANAGEMENT AND REPORTING
A key goal of the fault management system is to create a history of errors and faults that can be reviewed to understand the health of the system. To accomplish this goal, the history must be persistent across power cycles, etc. SNFM uses a filesystem based persistent storage to maintain the complete history of all activities.
ERROR AND FAULT LOGGING
Error and fault entries are reported in real time in persistent storage logs. While processing an error (i.e. the error collector), errors will be logged – an error entry is created, which is then stored in a database. Specific information relevant to each error event, such as the hardware component ID, will be stored as part of the error entry. At a later time, the error entry can be retrieved in order to display to a user, or to use while applying the policy during fault diagnosis.
Depending on the SNFM policy of the error, a fault entry could be created as well. The fault entry will be linked to the error that generated the fault.
SNFM APIS AND TOOLS
We provide APIs to retrieve system health details from SNFM. SNFM can be queried for component inventory statuses, error entries, and fault entries.
Components can be marked as absent, online, degraded, offline, or faulted as their inventory status.
- Absent: physically not connected or not available
- Online: physically present and healthy
- Degraded: component is present but operating at suboptimal performance
- Offline: component is taken offline to not be used usually due to software decisions
- Faulted: component is faulty and not usable
We also have a tool built on top of the APIs to display all components with their status, error entries, and fault entries. Both the APIs and the tools can be used for hardware debugging, testing for manufacturing, and chip bring up. Customers also have access to the APIs and tools in a production environment. See our public documentation for more details on the tool.
SNFM APIs can be used by other parts of the stack as well as used for building customer facing APIs. Error events can be forwarded as alerts to external client services near real time for recovery actions to be taken.
CONCLUSION
SNFM provides us with a myriad of benefits, ensuring the utmost reliability, availability, and serviceability (RAS).
The benefits of our solution include:
- System observability. With logging of error events, there is improved data collection for fault management metrics, including MTBF, MTTF, and failure rate, giving us the ability to analyze system performance and reliability.
- Higher Serviceability. System administrators can at-a-glance understand the overall health of their systems, as well quickly identify and address any potential problems.
- Improved Reliability. SNFM can help identify and report faulty components early so components can be repaired early. Therefore the system overall is more stable and has a lower chance of failure, hence more reliable.
- Improved Availability. In addition, automated recovery mechanisms allow our systems to be fully operational without human intervention for a longer period of time, meaning a reduced downtime.
One of the key characteristics of our system is performance for enterprise data center AI workloads, and SNFM policies reflect this by maintaining high availability with full system configuration and rapid recovery mechanisms. Accurately detecting the faults across the spectrum of hardware subsystems is also an important property of SNFM.