SambaNova delivers the first, full stack enterprise grade generative AI platform. Designed specifically for the enterprise, the SambaNova platform includes enterprise level features to deliver the highest levels of performance, reliability, and uptime. These include features for fault tolerance, management, and ease of serviceability.
Fault management plays a crucial role in enhanced reliability, error correction, and fault identification. As the complexity of a system increases, fault management becomes ever more important for enterprise customers that require the highest levels of availability. In this two-part blog, we discuss SambaNova Fault Management (SNFM), diving deeply into the intricacies of fault management within the SambaNova AI platform.
- In Part 1, we give some background. We explore the SambaNova product configuration, discuss errors, faults, and fault coverage, and finally give an overview of event sources.
- In Part 2, we dive more deeply into the architecture. First we discuss error handling, fault diagnosis, and fault handling for different types of faults. Next we explore error and fault logging and briefly explore APIs and tools.
At its core, this blog emphasizes our uncompromising commitment to reliability, availability, and serviceability (RAS) at the product level.
Summary:
- Fault management is an important component for ensuring the highest level of RAS.
- It is important to distinguish between Errors and Faults. In this context not all hardware errors result in the failure of hardware components.
- Hardware errors are handled by propagating them through various stages requiring error telemetry collection, fault diagnosis, and fault handling. The goal is to minimize operational disruptions and improve system health monitoring.
- Fault handling is performed based on the nature of a fault – some faults are automatically recovered while others require partial or full manual intervention to restore the system configuration.
FAULT MANAGEMENT AND METRICS
What is the need for fault management within our product offerings? To answer this question, it is prudent to go over the system configurations we offer across multiple generations of our product line. A data center rack form factor product needs to address certain metrics for product quality and reliability among other parameters, and fault management is the most critical parameter for system RAS.

SambaNova Systems offers enterprise class products, powered by AI accelerator chips which are based on our proprietary Reconfigurable Dataflow Architecture (RDA). These AI chips are named Reconfigurable Dataflow Units (RDUs) and are shipped together with host systems in SambaNova rack products. RDUs have a rich configuration of memory (more than 1TB) and IO interconnections (PCIe), and allow other PCIe devices to directly access the RDU memory. Each host is configured with 8 RDUs and these RDUs are part of external IO boxes (XRDUs) installed in the same rack. The XRDUs are connected to the host via PCIe IO interconnect and to each other via an isolated PCIe fabric domain.
This creates a robust and complex system IO topology that achieves the performance demands of modern enterprise AI workloads which scale across multiple hosts and racks.
Fault management is an integral part of SambaNova’s design philosophy which ensures optimized performance of RDU based data center rack solutions. We’ve adopted an efficient and practical approach for identifying faults, reporting the location of faulty hardware components, and maintaining a system inventory of all components. System inventory health is maintained by handling the hardware errors asynchronously and monitoring the hardware state periodically based on the component classifications we have created.
ERRORS, FAULTS, AND SNFM
Before diving into the details of our fault management solution, let us go over some critical terms which are applicable to any fault management system (FMS):
- Error: These are hardware reported error events or software detected errors which indicate an issue with the hardware component. The errors can be classified as correctable or uncorrectable. The correctable errors are normally handled by hardware. In the case of an uncorrectable error, there is a notification process to inform any software processes that may be impacted by the error.
- Fault: It is the classification of hardware error which indicates the component is operating at a non-optimal level i.e. component is not behaving properly as per system specifications. This state of a component is the outcome of fault diagnosis. The diagnosis is performed on error telemetry collected as part of handling the hardware error.
Each internal module of SambaNova’s FMS (a.k.a. SNFM) has different responsibilities. The following diagram shows the typical software components or modules of a fault management system. SNFM has combined the functionality shown in this diagram per the scope we defined for error collection and fault diagnosis.
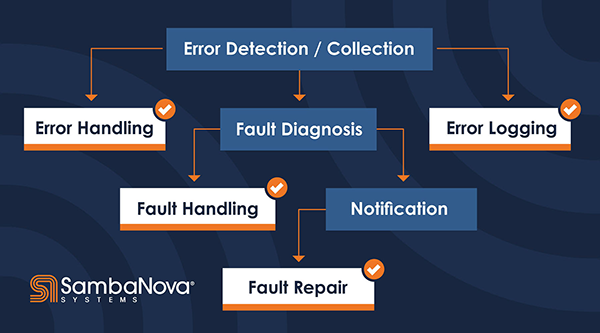
- Error handling: This module is responsible for collecting the error telemetry data and identifying the error type.
- Fault diagnosis: This module is responsible for performing the diagnosis on telemetry data. The diagnosis may result in faulting the hardware component. An important characteristic here is to locate the correct hardware component.
- Fault handling: This module is responsible for applying recovery actions in response to the detected faults. This includes initiating auto recovery on certain classes of components or reconfiguring the system to continue with reduced capacity to avoid system downtime.
- Logging/notification: The fault management system logs are separated into error, fault, and system inventory, and tools are provided for users to access these logs.
- Fault repair is performed after servicing the faulted hardware component and this includes manually clearing the faults after service.
FAULT COVERAGE METRICS
At this point, we have the basic organization of SNFM which brings us to another critical aspect of this system – key fault coverage metrics. The following confidence level metrics help us assess the effectiveness and reliability of SNFM in detecting and managing hardware failures:
- Fault detection: Represents the confidence level SNFM has in detecting the hardware failures. We can utilize techniques like logs and diagnostics to determine the level for this metric.
- Fault identification: Once a fault has been detected, SNFM must correctly identify the hardware subsystem or component responsible for the fault. Different subsystems can contribute to overall system failures, and we have to determine the accuracy of identifying the faulty subsystem.
- Fault localization: After identifying the faulty subsystem, SNFM must find the exact location of the component within the subsystem that is causing the failure. The precision of fault localization supports targeted repair or replacement actions.
These metrics provide insights into SNFM’s capabilities in detecting, identifying, and localizing failures. The robustness of these metrics helps us utilize SNFM right from system bring-up where hardware and systems teams can have better repairs for lab systems. The operations and manufacturing processes also depend upon a robust SNFM. This further extends our commitment to RAS for production systems at customer installations.
SOURCES OF EVENTS
As covered in Fault Management and Metrics, dynamic system health is maintained by managing errors and events from different sources across the system.
SNFM has to handle different classes of events, which can be generated by any of the hardware subsystems; these classes include initialization events, asynchronous events, monitored events, and externally reported events. These different classes of events are detected and reported differently, so part of SNFM’s responsibility is to provide interfaces for each of these situations.
Initialization of hardware subsystems can fail, which generates an event in the system. For example, PCIe initialization involves “training” specific links and checking their state; this training step can fail. If initialization fails the training step, the failure will be reported to SNFM, and the system state will reflect the result of the failed initialization.
The host receives asynchronous events (i.e. interrupts) from each RDU device on the host system; many of these interrupts correspond to error events that occur while using a device, so these events can be forwarded to SNFM to improve visibility. For example, while an application is using memory, an uncorrectable error may occur asynchronously, which could affect the correctness of the application; this event is sent to SNFM to make policy decisions about the use of the memory going forward. Additionally, the event is sent to the application, allowing the application to gracefully handle the error.
In order to detect certain events, the hardware subsystems may need to be actively monitored by the monitoring service in SNFM. For example, by polling on a status register in a specific hardware subsystem, events can be detected that are not sent asynchronously by the hardware subsystems. After actively detecting these events, the events are sent to SNFM to be processed.
Other parts of the software ecosystem can detect events that need to be forwarded to SNFM. For example, the board management controller (BMC) has visibility into different hardware subsystems; these events can affect the hardware subsystems managed by SNFM, so the events can be reported to improve visibility. Another example is when some of the hardware resources are provisioned in a virtual machine (VM). The VM might receive an event which affects the state of the bare metal machine’s resources, so the events can be forward between the VM and the bare metal machine.
ARCHITECTURE AND ERROR HANDLING
In this blog, you learned about fault management basics and SambaNova components. We then looked at some classes of events that SNFM has to handle. Clearly, a solid architecture and well-designed fault handling mechanisms are critical in enterprise environments. We will discuss more about the SNFM architecture and fault handling mechanisms in Part 2.