Deep learning frameworks have traditionally relied upon the 32-bit single-precision (FP32) format. However, FP32 computations require a significant amount of hardware resources, which limits performance. Recently, mixed precision training and inference, using a combination of 16-bit floating point (either half-precision - FP16 or brain-float - BF16) and FP32, have become common. Recent works [1] [2] [3] have demonstrated that machine learning models are tolerant to lower precision and mixed precision models can achieve the same accuracy as FP32 models with improved performance.
Inspired by these findings, popular ML frameworks have proposed mixed precision support. PyTorch’s automatic mixed precision (AMP) package [4] offers an autocast context manager that decides precision format for operators based on predetermined rules. TensorFlow [5] supports a simple mixed precision API that lets the user choose a global policy that fixes the same compute data type and variable data type for all the layers, but requires users to tune it by deciding what layers should be in any given precision.
SambaFlow 1.18 introduces support for mixed precision on RDUs. It streamlines the experience for model developers by adding new Python APIs to (i) directly control operator precision and (ii) enable compiler support for our novel Graph-Level Automatic Mixed Precision (GraphAMP) algorithm, which overcomes the limitations of existing frameworks.
Graph-level Automatic Mixed Precision
GraphAMP is a novel user-configurable graph-level automatic mixed precision algorithm that is implemented within the SambaFlow compiler starting with version 1.18. It downcasts numerically stable operators (such as matrix multiplication) and propagates the lower precision upstream in the graph as far as possible based upon the surrounding graph context. GraphAMP works for both inference and training.
SambaFlow allows the user to select from one of several possible GraphAMP presets. A preset assigns every operator to exactly one of three disjoint categories:
- Allowset: Operators’ inputs should be downcasted to lower precision. Suitable for numerically stable operations.
- Inferset: Operators’ input precision should be inferred from operator output precision. Suitable for numerically neutral operations.
- Denyset: Operators’ data types must remain unchanged. Suitable for numerically sensitive operations.
The algorithm traverses a model graph in the upstream direction, from the outputs to the inputs (not to be confused with the backpropagation algorithm for computing gradients during training). It conditionally alters the datatypes of tensor edges based on whether the connected downstream operators are in the allowset, inferset, or denyset. Thus, it converts any fp32 graph to a mixed precision graph and changes some operators from fp32 compute to mixed precision compute.
Note: In the SambaFlow 1.18, we are also releasing support for mixed precision compute in select operators, such as linear, matmul, softmax, and scaled_dot_product_attention operators. See the SambaFlow API Reference for details.
The nature of the mixed precision obtained from GraphAMP depends on how the operators are categorized within allowset/inferset/denyset. For example, to prioritize accuracy over performance, the user can select a conservative preset where most operators are assigned to the denyset. This prevents GraphAMP from optimizing most of the graph. Conversely, to prioritize performance but with more risk to accuracy, the user can select an aggressive preset where most operators are assigned to the allowset. A preset where all operators are in the denyset effectively disables GraphAMP completely.
For example, let’s consider the simple FP32 graph in the code snippet below. Suppose we are using a GraphAMP preset where only the matmul operator is in the allowset.
Python
def forward(self, a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
matmul_1 = torch.matmul(a, b)
act_1 = nn.GELU(matmul_1)
matmul_2 = torch.matmul(act_1, c)
out = nn.GELU(matmul_2)
return outWhen this graph is compiled by SambaFlow, GraphAMP converts the matmuls into mixed precision (BF16 inputs, accumulation in FP32, and output in FP32) and leaves all of the other operators unchanged, as shown in the figure below.
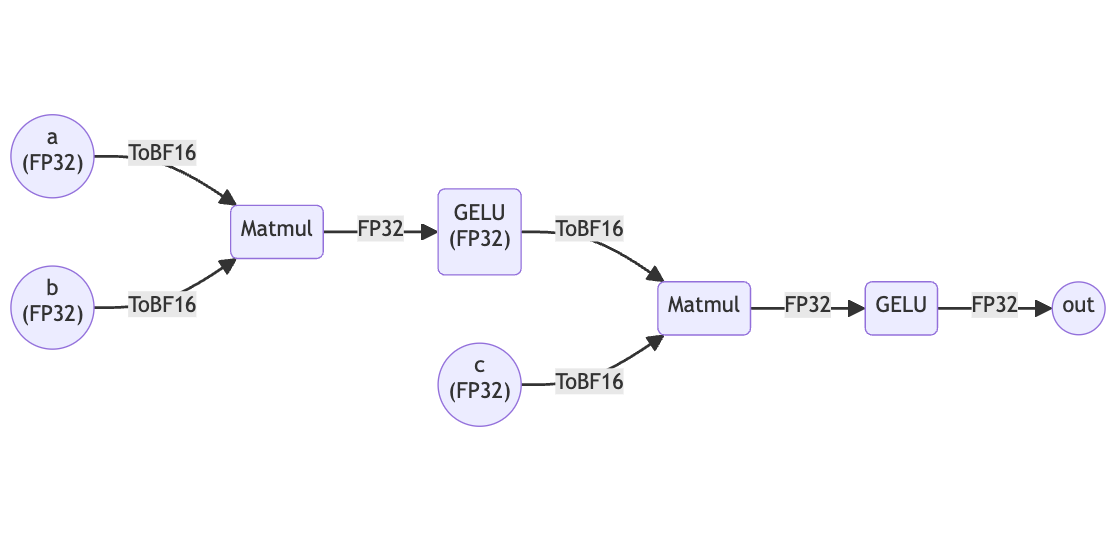
Model developers may want only some operator instances to be in lower precision. SambaFlow keeps the user in control by letting them selectively disable GraphAMP for any part of the graph. We offer instance overrides at the model level, where users can define regions of the model that are to not be touched by GraphAMP through a context manager. Users can manually adjust the precision of a subgraph within the context manager, while still taking advantage of the benefits of GraphAMP for the remaining portion of the model graph. Thus, users can benefit from the convenience of GraphAMP without being constrained by its presets.
The following example illustrates how the user can override GraphAMP to achieve a specific outcome. Using the same graph as before, suppose the user wishes to run the second GELU in BF16 while leaving all other GELUs in FP32 (it is still in the denyset). The user places the second matmul (matmul_2) and GELU (out) within the disable_graphamp context manager.
Python
def forward(self, a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
matmul_1 = torch.matmul(a, b)
act_1 = nn.GELU(matmul_1)
with disable_graphamp():
matmul_2 = torch.matmul(act_1.bfloat16(), c.bfloat16())
out = nn.GELU(matmul_2)
return out
When the above model is compiled by SambaFlow, the graph will be transformed by GraphAMP as shown in the figure below.
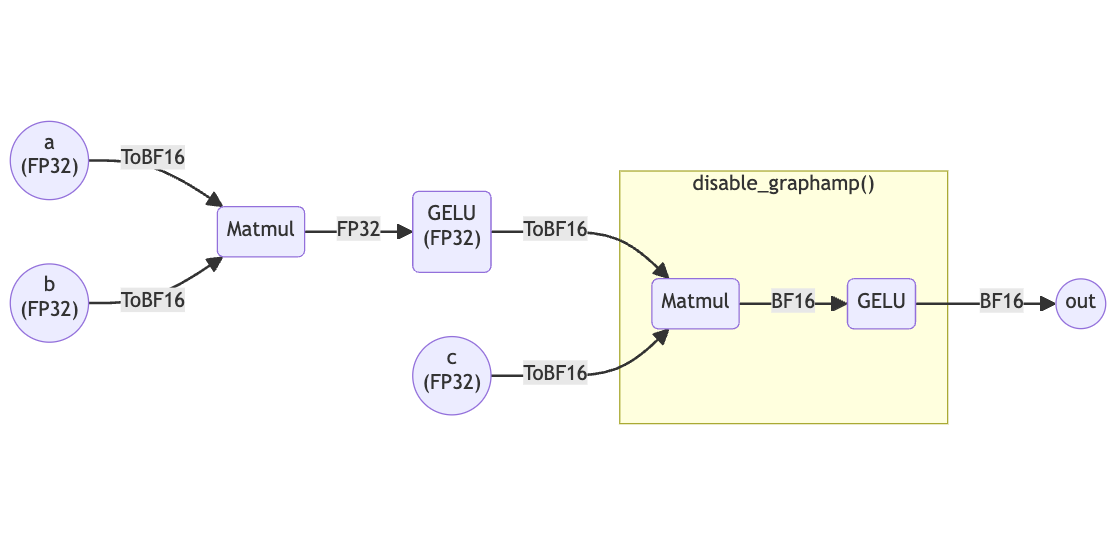
Additional Mixed Precision Controls
In addition to GraphAMP and instance overrides, the SambaFlow compiler also offers fine-grained control over the precision used when performing tiling accumulation (training and inference), weight gradient reduction (training only), and weight updates (training only).
- Tiling is a compiler optimization that improves performance by taking advantage of data locality on chip. If a tensor is tiled along a reduction dimension then the model accuracy can be sensitive to the precision of cross-tile accumulation. The
--tiling-accumflag lets the user specify either FP32 or BF16 precision for tiling accumulation. Using FP32 ensures high accuracy but can impact performance. - The precision of weight gradient reduction across workers can also impact model accuracy. The user can control it with the
--weight-grad-reduceflag, which supports FP32 and BF16 precision. Using FP32 ensures high accuracy but can impact performance. - In the SambaFlow 1.18 release, we have also added support for an FP32 weight update mode based on the mixed precision training insights discussed by Micikevicius et al [1].
For more information, please refer to our SambaFlow 1.18 documentation about mixed precision.
[1] P. Micikevicius et al., "Mixed precision training", arXiv:1710.03740, 2017, [online] Available: http://arxiv.org/abs/1710.03740.
[2] P. Zamirai et al., “Revisiting BF16 Training”, arXiv: 2010.06192, 2021, [online] Available: https://arxiv.org/abs/2010.06192.
[3] M. Dörrich et al., "Impact of Mixed Precision Techniques on Training and Inference Efficiency of Deep Neural Networks," in IEEE Access, 2023, [online] Available:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10146255
[4] “AUTOMATIC MIXED PRECISION PACKAGE - TORCH.AMP”, Available: https://pytorch.org/docs/stable/amp.html#automatic-mixed-precision-package-torch-amp
[5] “Mixed Precision in Tensorflow”, Available: https://www.tensorflow.org/guide/mixed_precision