 SambaNova is excited to open source a collection of expert models that adapt Llama 2 [12] to a diverse set of 9 languages. The SambaLingo language expert models achieve state of the art results on multi-lingual quantitative and qualitative benchmarks when compared to open source multilingual model baselines such as XGLM-7B [44], BLOOM-7B [45], mGPT-13B [46] and even expert models such as Jais-13B [36] and ELYZA-7b [33]. SambaNova is releasing two variants for each model: a base pretrained checkpoint and a chat version of the checkpoint, which aligns the model with human preferences data using Direct Preference Optimization (DPO) [2]. These Arabic, Thai, Turkish, Japanese, Hungarian, Russian, Bulgarian, Serbian and Slovenian language experts can be found on SambaNova’s Hugging Face page or linked directly in Appendix A.
SambaNova is excited to open source a collection of expert models that adapt Llama 2 [12] to a diverse set of 9 languages. The SambaLingo language expert models achieve state of the art results on multi-lingual quantitative and qualitative benchmarks when compared to open source multilingual model baselines such as XGLM-7B [44], BLOOM-7B [45], mGPT-13B [46] and even expert models such as Jais-13B [36] and ELYZA-7b [33]. SambaNova is releasing two variants for each model: a base pretrained checkpoint and a chat version of the checkpoint, which aligns the model with human preferences data using Direct Preference Optimization (DPO) [2]. These Arabic, Thai, Turkish, Japanese, Hungarian, Russian, Bulgarian, Serbian and Slovenian language experts can be found on SambaNova’s Hugging Face page or linked directly in Appendix A.
While large language models such as Llama 2 have gained widespread popularity, there remains a wide gap in their capabilities between English and other languages. To combat this, models like BLOOM [42], XGLM [43], and AYA [6] have been trained to be multilingual; however, their performance in other languages still falls short of the state-of-the-art standards. Consequently, the majority of the world is left without access to high quality open source AI models in their native tongue. This work shows that English centric language models such as Llama 2 can be adapted to any new language and outperform all existing open source multilingual models on a majority of benchmarks. Additionally, we develop a recipe for aligning the adapted checkpoints for effective responses to user queries in the adapted language, leveraging human preference data. Our results demonstrate a preference for our models' responses over open-source alternatives, and we welcome everyone to try these models by visiting SambaLingo-chat-space.
Evaluation
We measure the models’ capability on the new languages with a mix of canonical multilingual NLP benchmarks, including evaluation perplexity, translation, question answering, text classification, and natural language understanding. We do not include AYA-101 [6] as a baseline in these benchmarks because it is an instruction tuned checkpoint, and many of the benchmarks are contaminated in its training data. Also, to test the English capability of the model after bilingual training, we evaluate the models on OpenLLM Leaderboard [23]. Lastly, for the chat version of the models, we test their ability with prompt datasets written in the native language and use GPT-4 as a judge.
Quantitative Evaluation
Evaluation Perplexity
We report the “perplexity” on a holdout set of training text, Wikipedia [21] and a random sample of MC4 [22]. Evaluating perplexity on all three datasets has approximately the same result, below we show the perplexity on the holdout training data. All evaluation is done with EleutherAI’s lm-eval-harness [13]. Our models achieve state of the art perplexity compared to every open source baseline.
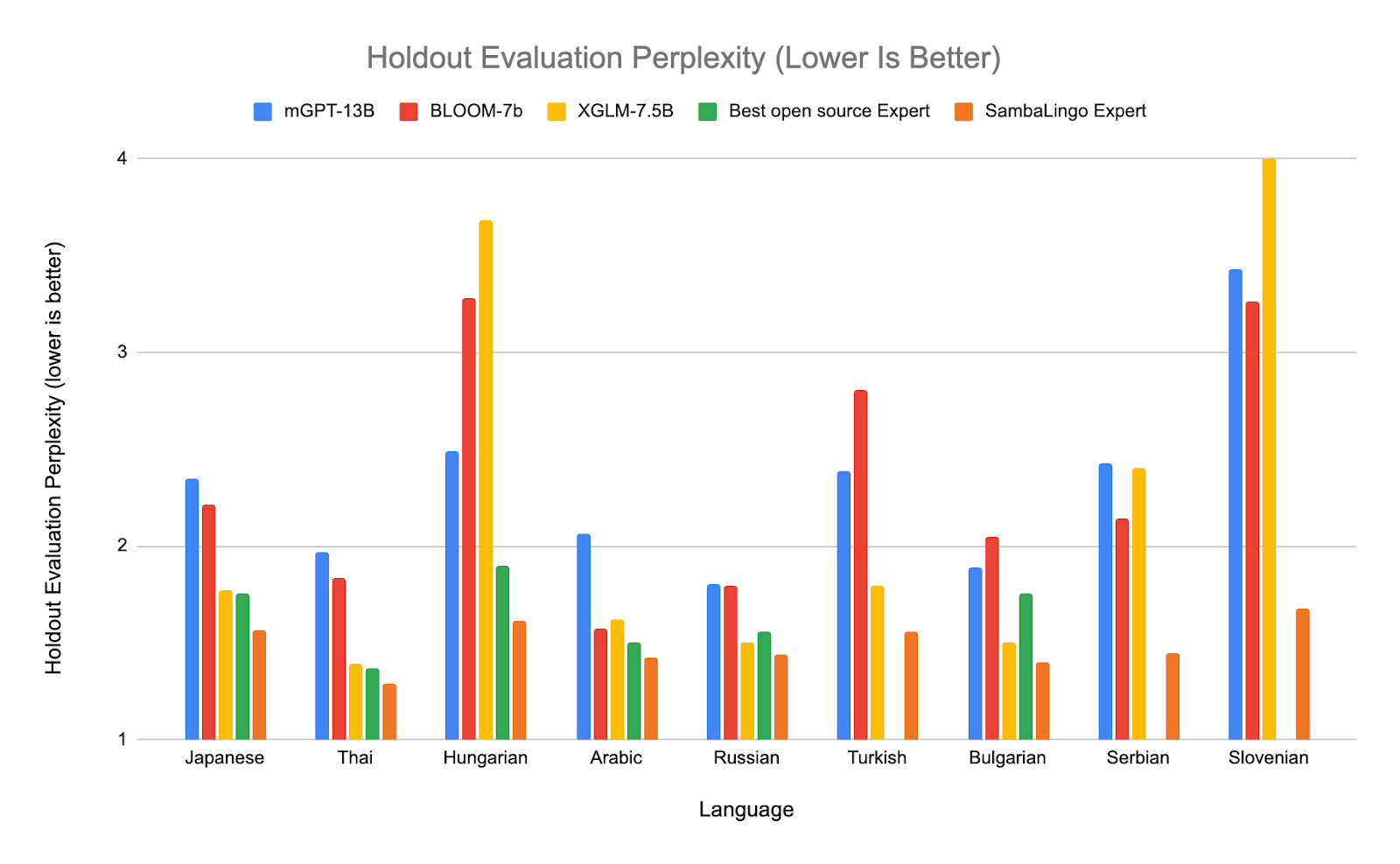 Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Translation - FLORES-200
All SambaLingo expert models are bi-lingual (English and the expert language), and they exhibit state of the art performance on translation tasks. We evaluate our base pretrained checkpoints on the FLORES-200 dataset [15] with 8 shot evaluation using the ‘{IN}={OUT}’ prompt as recommended by Zhu et al [14].
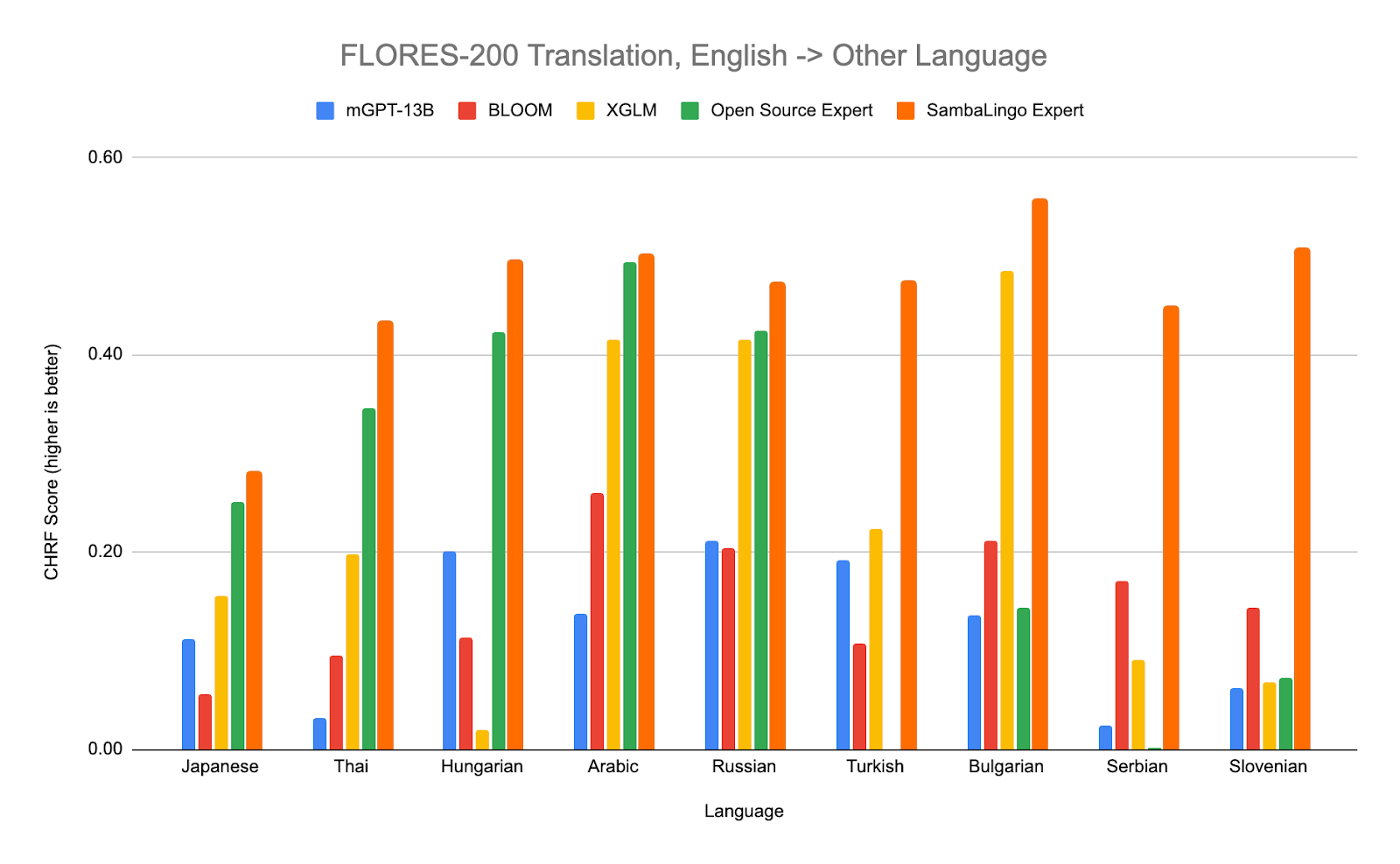
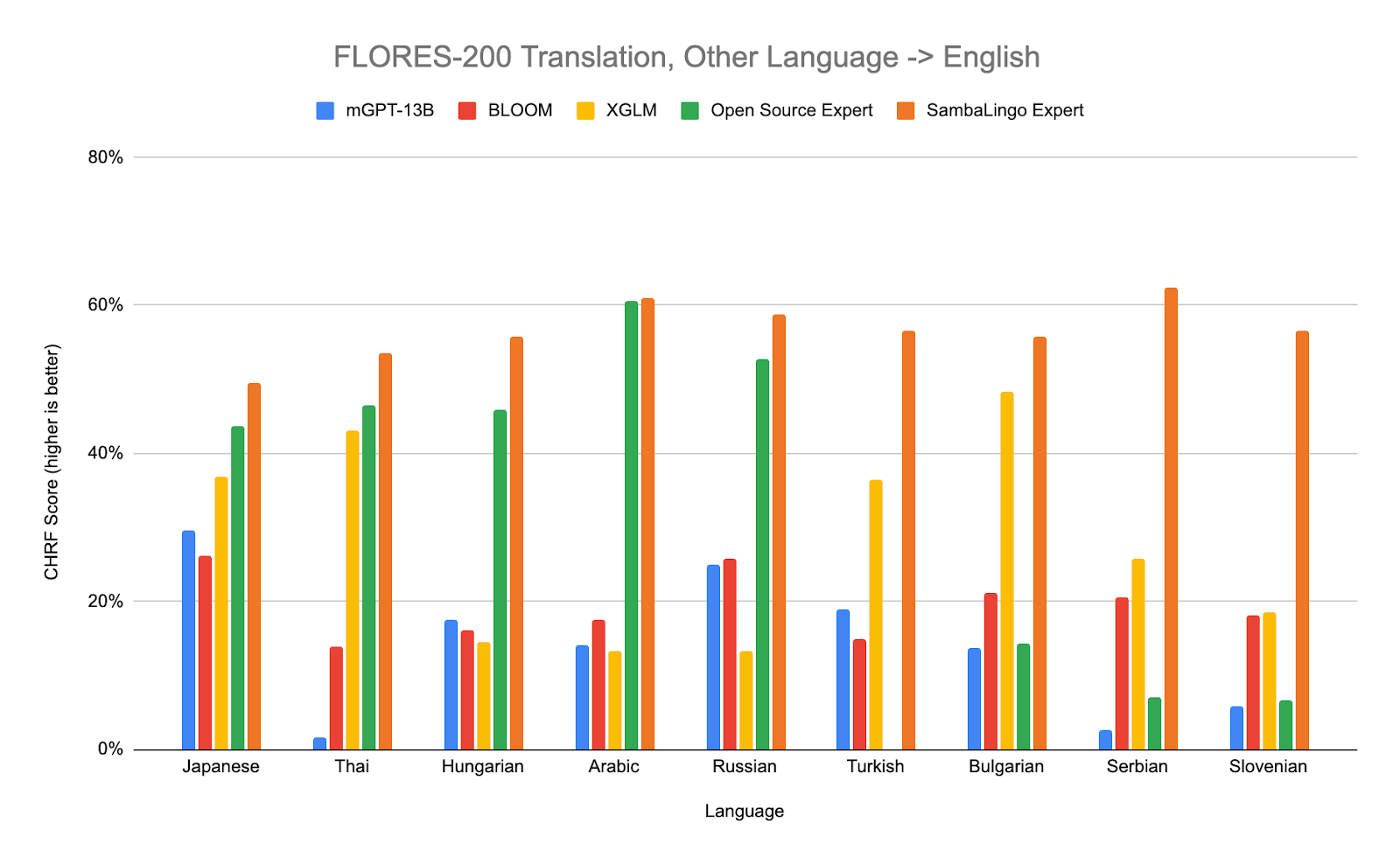
Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Multiple Choice Question Answering - BELEBELE
We measure the model's ability to answer multiple choice questions using the BELEBELE dataset [16]. We perform 3 shot evaluation on our base checkpoints with the default prompt from the BELEBELE github repo [17] and select the answer with the lowest perplexity.
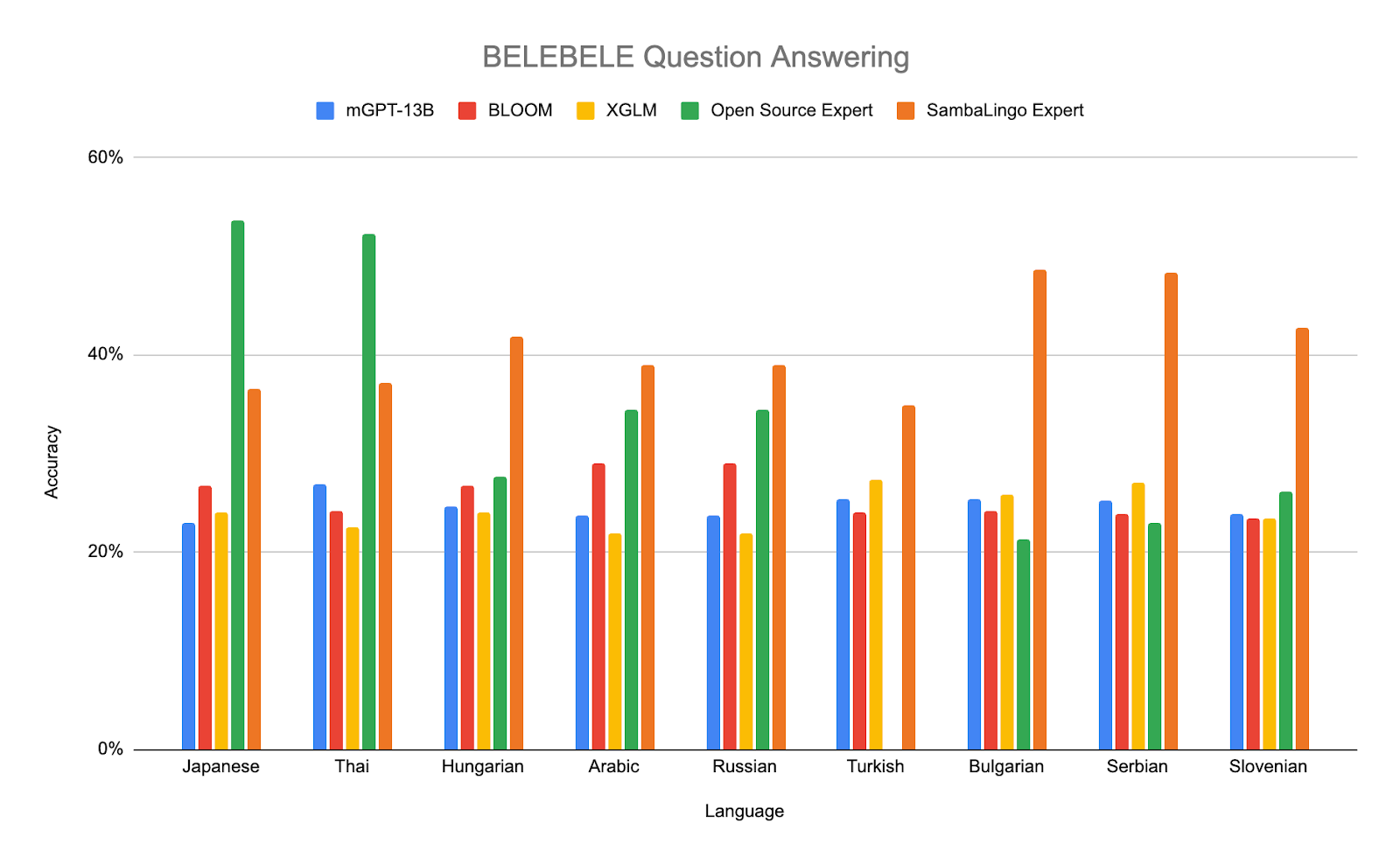 Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Text Classification - SIB-200
Text classification is a task that asks the model to categorize a piece of text. We evaluate the base pre-trained language experts on the SIB-200 benchmark using the prompt recommended by Lin et al [18] with a 3 shot context and select the answer with the lowest perplexity.
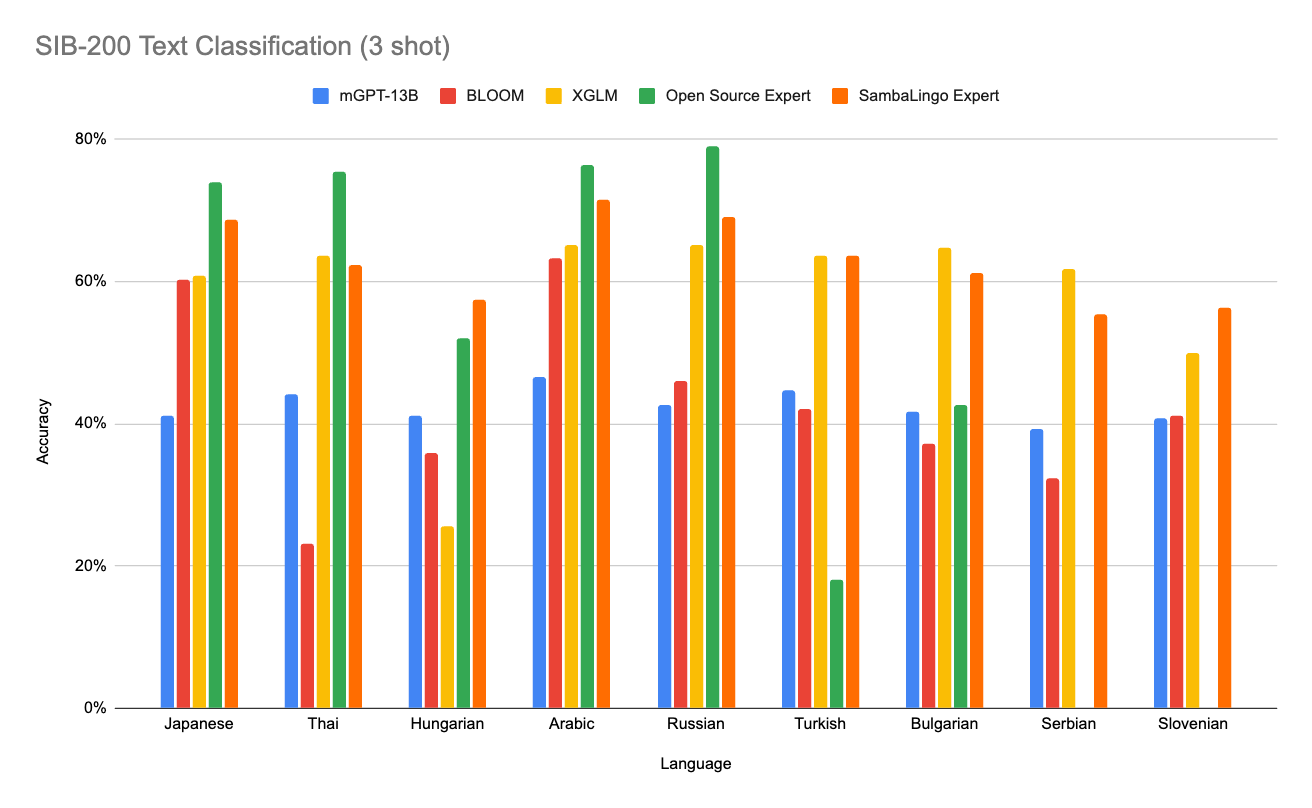 Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
Natural Language Understanding - XNLI, XWinograd, PAWS-X, XCOPA, XStoryCloze
Natural language understanding helps show the model's ability to grasp the meaning, context, and nuances inherent in human language. We evaluate using XNLI [47], XWinograd [49], PAWS-X [51], XCOPA [48], XStoryCloze [43] multilingual benchmarks from lm-eval-harness [13] with 0 shot context.
| mGPT-13B | BLOOM | XGLM | Open Source Expert | SambaLingo Expert | |
| Arabic | 0.516 | 0.585 | 0.562 | 0.633 | 0.662 |
| Russian | 0.594 | 0.527 | 0.562 | 0.690 | 0.717 |
| mGPT-13B | BLOOM | XGLM | Open Source Expert | SambaLingo Expert | |
| Japanese | 0.578 | 0.589 | 0.650 | 0.776 | 0.766 |
| Russian | 0.600 | 0.571 | 0.632 | 0.667 | 0.692 |
| mGPT-13B | BLOOM | XGLM | Open Source Expert | SambaLingo Expert | |
| Thai | 0.528 | 0.554 | 0.594 | 0.606 | 0.614 |
| Turkish | 0.568 | 0.512 | 0.584 | 0.558 | 0.694 |
| mGPT-13B | BLOOM | XGLM | Open Source Expert | SambaLingo Expert | |
| Japanese | 0.452 | 0.454 | 0.520 | 0.505 | 0.468 |
| mGPT-13B | BLOOM | XGLM | Open Source Expert | SambaLingo Expert | |
| Thai | 0.392 | 0.349 | 0.437 | 0.430 | 0.447 |
| Arabic | 0.334 | 0.338 | 0.334 | 0.363 | 0.336 |
| Russian | 0.454 | 0.426 | 0.334 | 0.498 | 0.353 |
| Turkish | 0.387 | 0.350 | 0.462 | 0.384 | 0.339 |
| Bulgarian | 0.458 | 0.394 | 0.449 | 0.338 | 0.428 |
Open Source Expert Baselines: Japanese: ELYZA-japanese-Llama-2-7b [33], Thai: typhoon-7b [34], Arabic : jais-13b [36], Hungarian: NYTK/PULI-GPTrio [35], Russian: saiga_mistral_7b_merged [37], Turkish: TURNA [38], Bulgarian: mGPT-1.3B-bulgarian [39], Serbian: sr-gpt2 [40], Slovenian: sl-gpt2 [41]
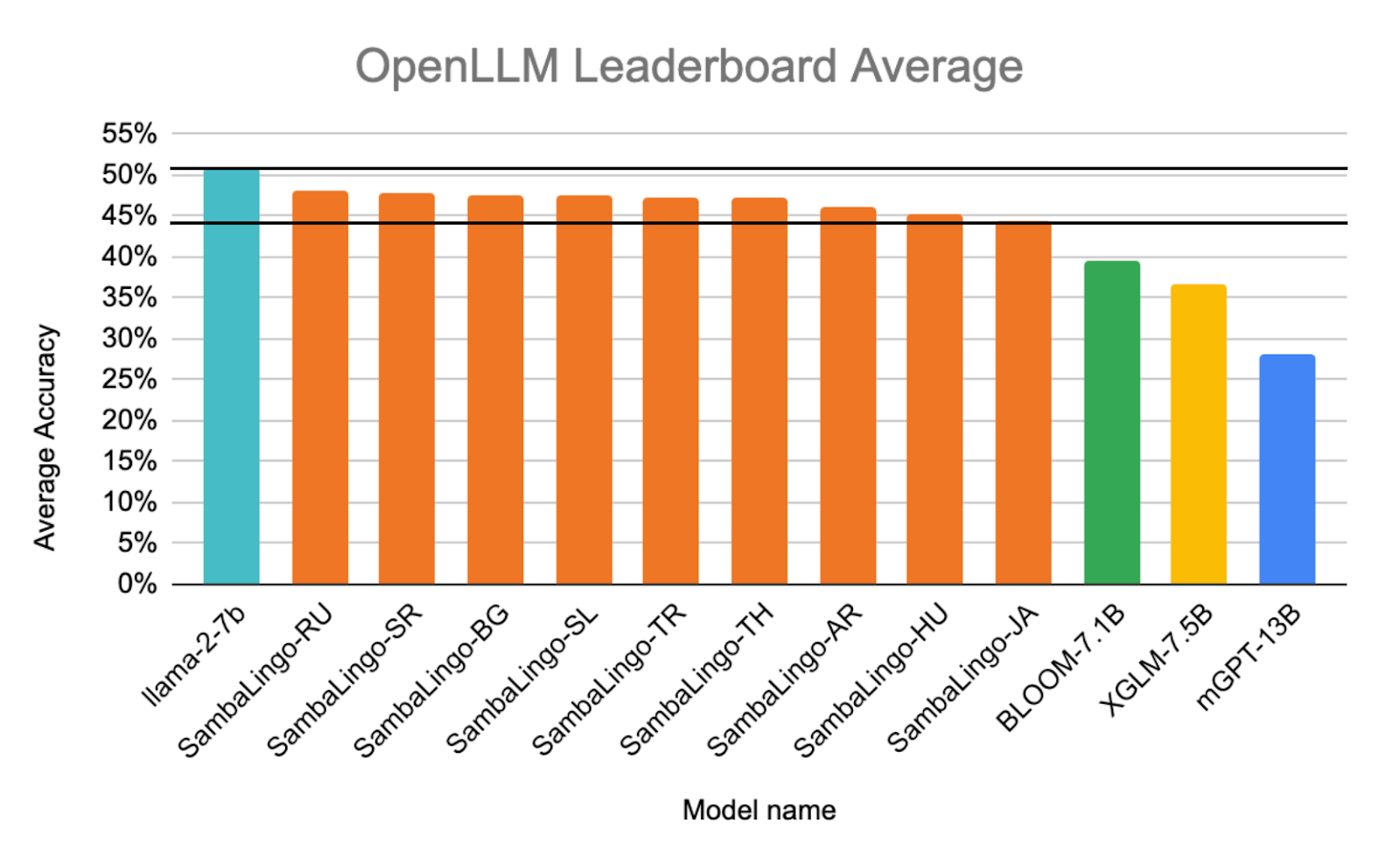
English - OpenLLM Leaderboard
In order to test how our models retrain their English capabilities after being adapted to new languages, we evaluate them on the standard OpenLLM leaderboard benchmarks [23]. We followed the same few-shot numbers in the OpenLLM leaderboard repository. We find that there are regressions on our model compared to base Llama, but our models still retain their ability to outperform existing multilingual model baselines in English.
Qualitative Evaluation
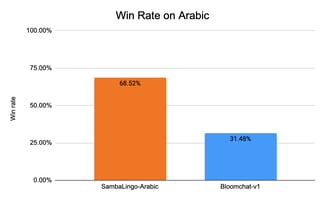
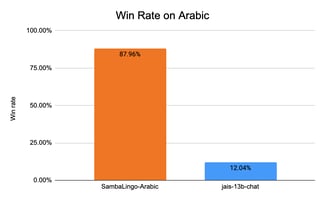
In order to test SambaLingo-Chat’s ability to generate high quality responses to real user prompts, we measure the win rate with GPT4 as a judge [19][20]. We test SambaLingo-Chat’s ability on Arabic, Japanese, and Turkish and then evaluate the win rate against the best open source models for those languages. We did not cherry pick the prompts or models we present in this section.
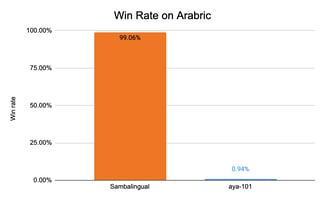
For Arabic, we compare against aya-101 [6], Jais-13b-chat [7], and Bloomchat-v1 [8]. We used the prompts from x-self-instruct-seed-32 [10] and xOA22 [11]. Sambalingo-Arabic-Chat reaches 87.96% win rate compared to Jais-13B-chat, 99.06% win rate compared to Aya101, and 68.52% compared to Bloomchat-v1.
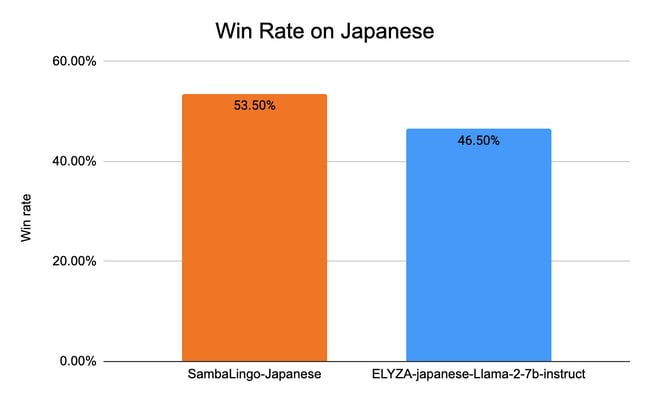
For Japanese, we compare against ELYZA-japanese-Llama-2-7b-instruct [5]. We randomly sampled 100 prompts from the training set of aya_dataset [9]. Sambalingo-Japanese-Chat reaches a 53.5% win rate in the comparison.
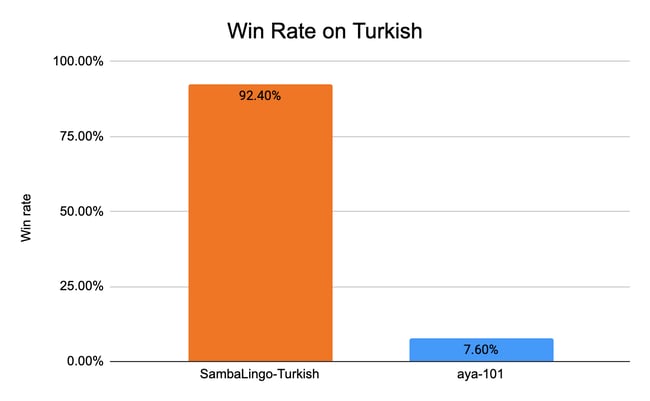
 For Turkish, we compare against aya-101 [6]. We used the prompts from the test set of aya_dataset [9]. Sambalingo-Turkish-Chat reaches 92.4% win rate in the comparison.
For Turkish, we compare against aya-101 [6]. We used the prompts from the test set of aya_dataset [9]. Sambalingo-Turkish-Chat reaches 92.4% win rate in the comparison.
Training Methodology
Continuous pretraining
Base Model - Llama 2
All of our models are continuously pretrained from the Llama 2 base model [12]. We run continuous pre-training for a total of 400 billion tokens across all the language experts, accelerated by SambaNova’s RDUs [24].
Vocabulary Extension
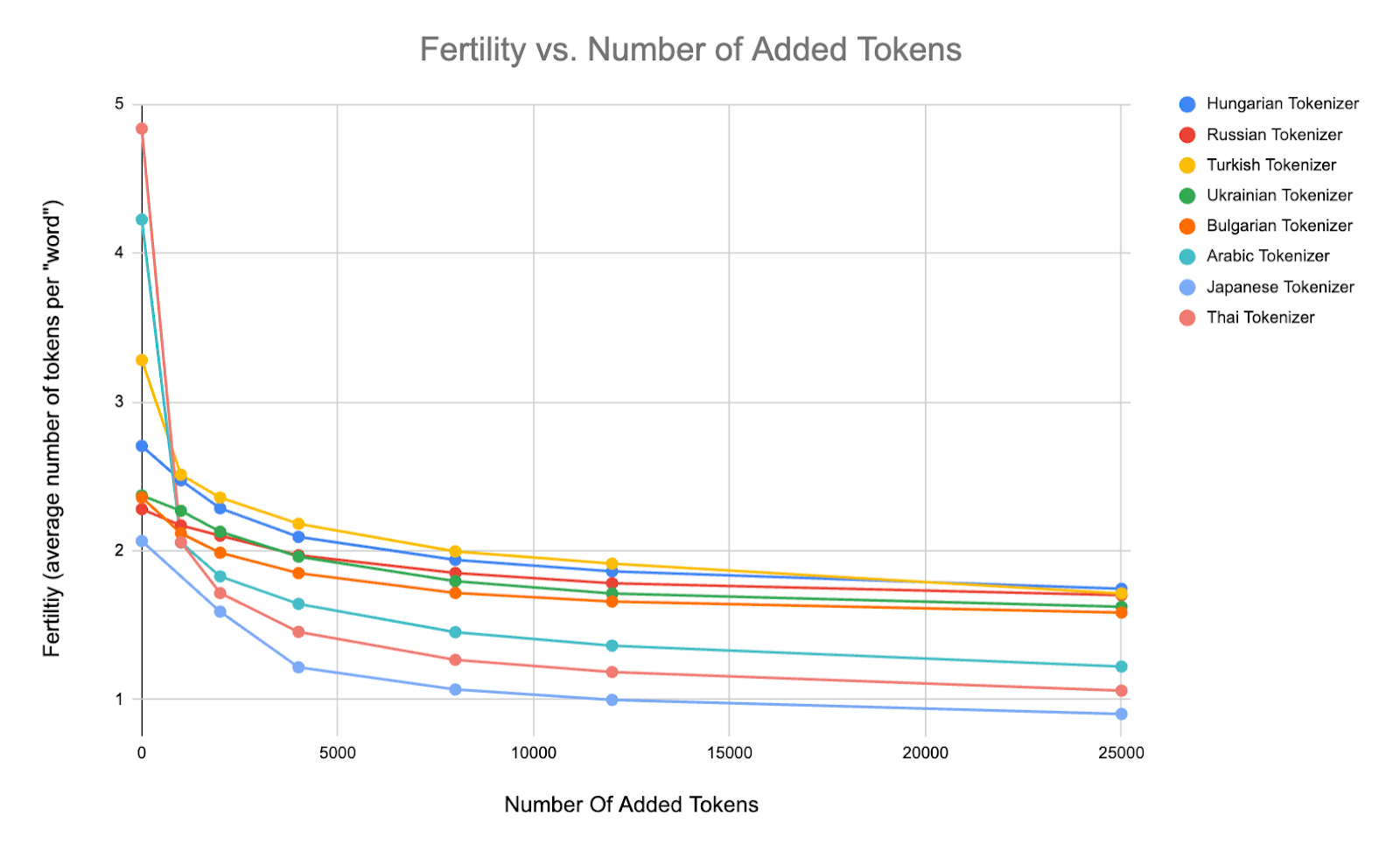
The Llama tokenizer is an English centric tokenizer, which means that it will not efficiently tokenize text in other languages. Previous work [25, 27] has shown that continuously pretrained models can learn newly added tokens. A tokenizer with added tokens allows more text to be packed into fewer tokens, so this gives our model improved training/inference efficiency and a longer effective sequence length. The plot below shows how the tokenizer fertility (average number of tokens per “word”) [28] improves as more tokens are added in each language. In some languages, such as Thai, it improves by as much as 4x.
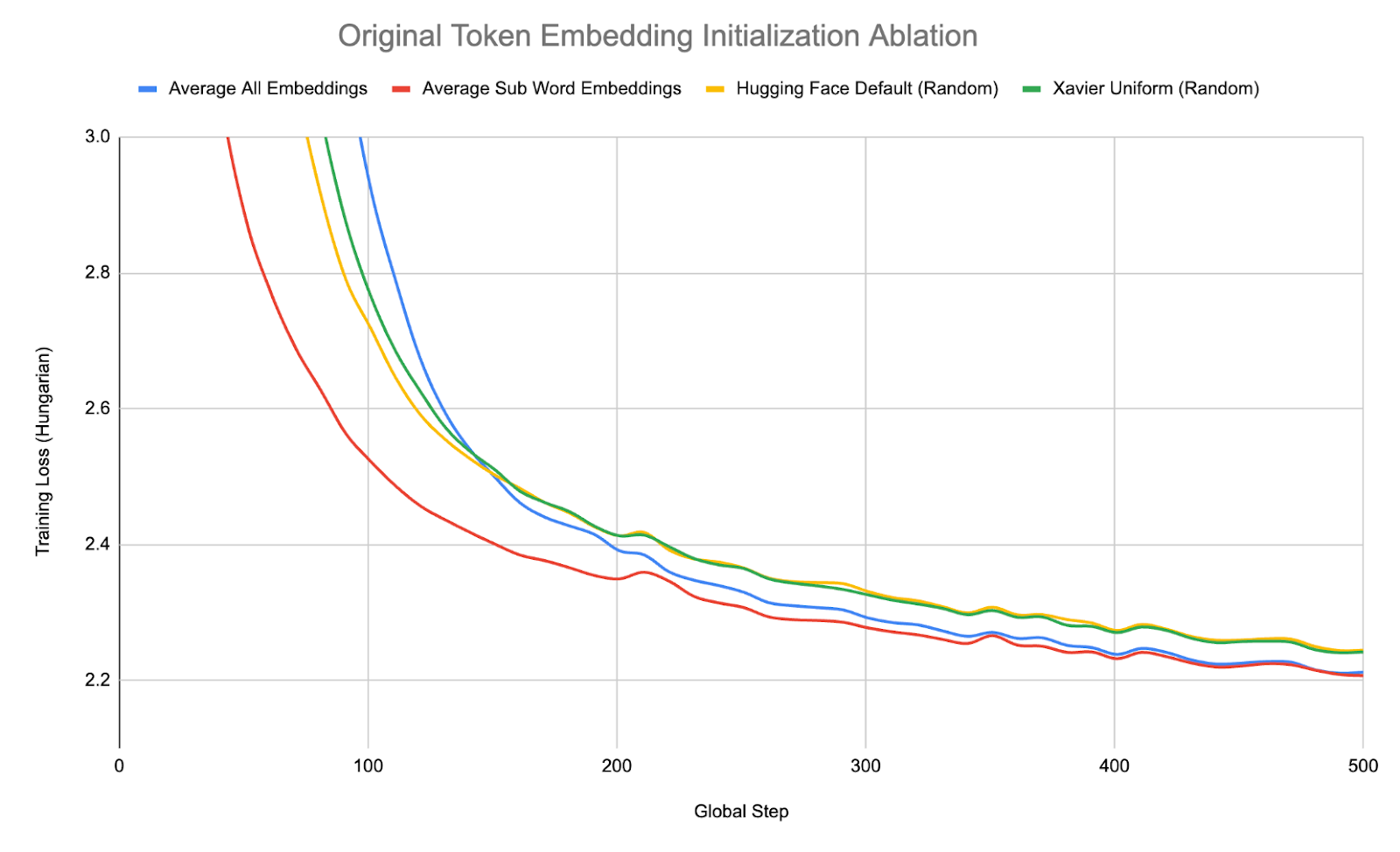
 We extended the vocabulary of the base llama model from 32,000 tokens to 57,000 tokens by adding up to 25,000 non-overlapping tokens from the new language. In order to initialize the embeddings of these newly added tokens, we experiment with various initialization methods:
We extended the vocabulary of the base llama model from 32,000 tokens to 57,000 tokens by adding up to 25,000 non-overlapping tokens from the new language. In order to initialize the embeddings of these newly added tokens, we experiment with various initialization methods:
- Hugging Face default: a standard normal initialization with 0 mean, 0.02 standard deviation
- Xavier Uniform: A uniform distribution, with a range defined by the size of the new embedding [31]
- Average all: Initialize all new embeddings with the mean of all previous embeddings [52]
- Average subword: For each new token t, let L_t = [t1,...,tk] be the list of k tokens that t would have been tokenized as under the original tokenizer. Initialize the embedding E(t) with mean(E(L_t)) = mean([E_t1,...,E_tk]) [29, 30]
We run a training ablation with the above methods for 20 million tokens, and find that initializing by averaging the token sub-words has the lowest training loss, so we initialize all of our new token embeddings using this method. We further find that it helps to initialize the LM head embeddings in the same fashion, as Llama 2 does not tie its token embedding and LM head weights.
 Training Details
Training Details
All pre-training is done on the cultura-X dataset [26]. We mix the data to be 75% data from the language we are adapting to, and 25% English as suggested by Csaki et al [25]. We pack the data into sequences of length 4096, and ensure that when learning a token we only attend to previous tokens in the context of the corresponding text document. We train with a global batch size of 1024, sequence length of 4096, maximum learning rate of 1e-4 with cosine decay, warmup ratio of 0.01 and a weight decay of 0.1. We train each expert for up to 4 epochs [32], but as there is a varying amount of data for each language, we do not reach 4 epochs for most training runs.
Alignment
The alignment phase follows the recipe for Zephyr-7B [1], and comprises two stages: supervised fine-tuning (SFT) and Direct Performance Optimization (DPO) [2].
The SFT phase was done on the ultrachat_200k dataset [3] mixed with the Google translated version of the ultrachat_200k dataset. It was trained for one epoch with global batch size 512 and max sequence length 2048 tokens. We used a linear decay learning rate of 2e-5 and 10% warmup.
The DPO phase was done on the ultrafeedback dataset [4] and cai-conversation-harmless dataset [50], mixed with 10% of the data Google translated. It was trained with global batch size 32 and for three epochs. We used a linear decay learning rate of 5e-7, 10% warmup and β=0.1 as the regularization factor for DPO.
Acknowledgements
We extend our heartfelt gratitude to the open-source AI community; this endeavor would not have been achievable without open source. SambaNova embraces the open-source community and aspires to actively contribute to this initiative.
We would like to give a special thanks to the following groups
- Meta for open sourcing LLama 2 and open sourcing FLORES-200 dataset
- Nguyen et al for open sourcing CulturaX dataset
- CohereAI for releasing AYA-101 and open sourcing a multilingual instruction tuning dataset
- EleutherAI for their open source evaluation framework
- Hugging Face-H4 team for open source the Zephyr training recipe and alignment handbook repo
Appendix A - Links to Hugging Face Model
https://huggingface.co/sambanovasystems/SambaLingo-Arabic-Basehttps://huggingface.co/sambanovasystems/SambaLingo-Arabic-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Bulgarian-Base
https://huggingface.co/sambanovasystems/SambaLingo-Bulgarian-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Hungarian-Base
https://huggingface.co/sambanovasystems/SambaLingo-Hungarian-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Japanese-Base
https://huggingface.co/sambanovasystems/SambaLingo-Japanese-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Russian-Base
https://huggingface.co/sambanovasystems/SambaLingo-Russian-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Slovenian-Base
https://huggingface.co/sambanovasystems/SambaLingo-Slovenian-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Serbian-Base
https://huggingface.co/sambanovasystems/SambaLingo-Serbian-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Thai-Base
https://huggingface.co/sambanovasystems/SambaLingo-Thai-Chat
https://huggingface.co/sambanovasystems/SambaLingo-Turkish-Base
https://huggingface.co/sambanovasystems/SambaLingo-Turkish-Chat
Appendix B - Example Generations
Citations
[1] https://arxiv.org/pdf/2310.16944.pdf[2] https://arxiv.org/abs/2305.18290
[3] https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k
[4] https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized
[5] https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-instruct
[6] https://huggingface.co/CohereForAI/aya-101
[7] https://huggingface.co/core42/jais-13b-chat
[8] https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1
[9] https://huggingface.co/datasets/CohereForAI/aya_dataset
[10] https://huggingface.co/datasets/sambanovasystems/x-self-instruct-seed-32
[11] https://huggingface.co/datasets/sambanovasystems/xOA22
[12] https://arxiv.org/pdf/2307.09288.pdf
[13] https://github.com/EleutherAI/lm-evaluation-harness
[14] https://arxiv.org/pdf/2304.04675.pdf
[15] https://github.com/facebookresearch/flores/blob/main/flores200/README.md
[16] https://arxiv.org/abs/2308.16884
[17] https://github.com/facebookresearch/belebele
[18] https://arxiv.org/pdf/2401.13303.pdf
[19] https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge
[20] https://arxiv.org/abs/2306.05685
[21] https://huggingface.co/datasets/wikimedia/wikipedia
[22] https://huggingface.co/datasets/mc4
[23] https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
[24] https://sambanova.ai/hubfs/23945802/SambaNova_Accelerated-Computing-with-a-Reconfigurable-Dataflow-Architecture_Whitepaper_English-1.pdf
[25] https://arxiv.org/abs/2311.05741
[26] https://arxiv.org/pdf/2309.09400.pdf
[27] https://arxiv.org/pdf/2312.02598.pdf
[28] https://juditacs.github.io/2019/02/19/bert-tokenization-stats.html
[29] https://arxiv.org/pdf/2311.00176.pdf
[30] https://aclanthology.org/2021.emnlp-main.833.pdf
[31] https://pytorch.org/docs/stable/nn.init.html#torch.nn.init.xavier_uniform_
[32] https://arxiv.org/pdf/2305.16264.pdf
[33] https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b
[34] https://huggingface.co/scb10x/typhoon-7b
[35] https://huggingface.co/NYTK/PULI-GPTrio
[36] https://huggingface.co/core42/jais-13b
[37] https://huggingface.co/IlyaGusev/saiga_mistral_7b_merged
[38] https://huggingface.co/boun-tabi-LMG/TURNA
[39] https://huggingface.co/ai-forever/mGPT-1.3B-bulgarian
[40] https://huggingface.co/macedonizer/sr-gpt2
[41] https://huggingface.co/macedonizer/sl-gpt2
[42] https://huggingface.co/docs/transformers/model_doc/bloom
[43] https://arxiv.org/abs/2112.10668
[44] https://huggingface.co/facebook/xglm-7.5B
[45] https://huggingface.co/bigscience/bloom-7b1
[46] https://huggingface.co/ai-forever/mGPT-13B
[47] https://arxiv.org/abs/1809.05053
[48] https://aclanthology.org/2020.emnlp-main.185.pdf
[49] https://github.com/yandex-research/crosslingual_winograd
[50] https://huggingface.co/datasets/HuggingFaceH4/cai-conversation-harmless
[51] https://arxiv.org/abs/1908.11828
[52] https://nlp.stanford.edu/~johnhew/vocab-expansion.html