Many of our customers are finding that while closed source models from OpenAI and Anthropic work well for general tasks, they do not perform well enough to be applied to their core business, where specialized-task performance, cost to run at scale, and model ownership become important. Today, we’d like to share with you how we’ve helped those customers use AI to automate these proprietary tasks with fine-tuned open source models. This higher quality allows customers to unlock automation that is not available with general models, all while running 13x faster and 33x cheaper than GPT-4o, and residing in an owned model that they can use with sensitive data, inside their firewall.
In this article we describe an end-to-end solution leveraging exclusively open-source LLMs to
- Generate a Q&A dataset for fine-tuning smaller and faster models:
- Extract data from documents and use Llama 3 8B at over 1000 tokens/s to generate thousands of Q&A pairs.
- Fine-tune Llama 3 70B to filter out low-quality Q&A pairs and run the dataset quality control step at over 570 tokens/s.
- Build a RAG application
- Fine-tune open-source embeddings (like Microsoft’s E5 Large V2) to produce a high-speed and highly accurate retrieval pipeline beating Open AI’s SOTA embedding: Text Embedding 3 Large.
- Fine-tune open-source LLMs (like Llama 3 8B) to generate answers from the retrieved context at 1000 tokens/s and more accurately than Open AI’s SOTA GPT4-o.
- Evaluate the RAG answers using Llama 3.1 405B, which has been shown to provide SOTA judging performance.
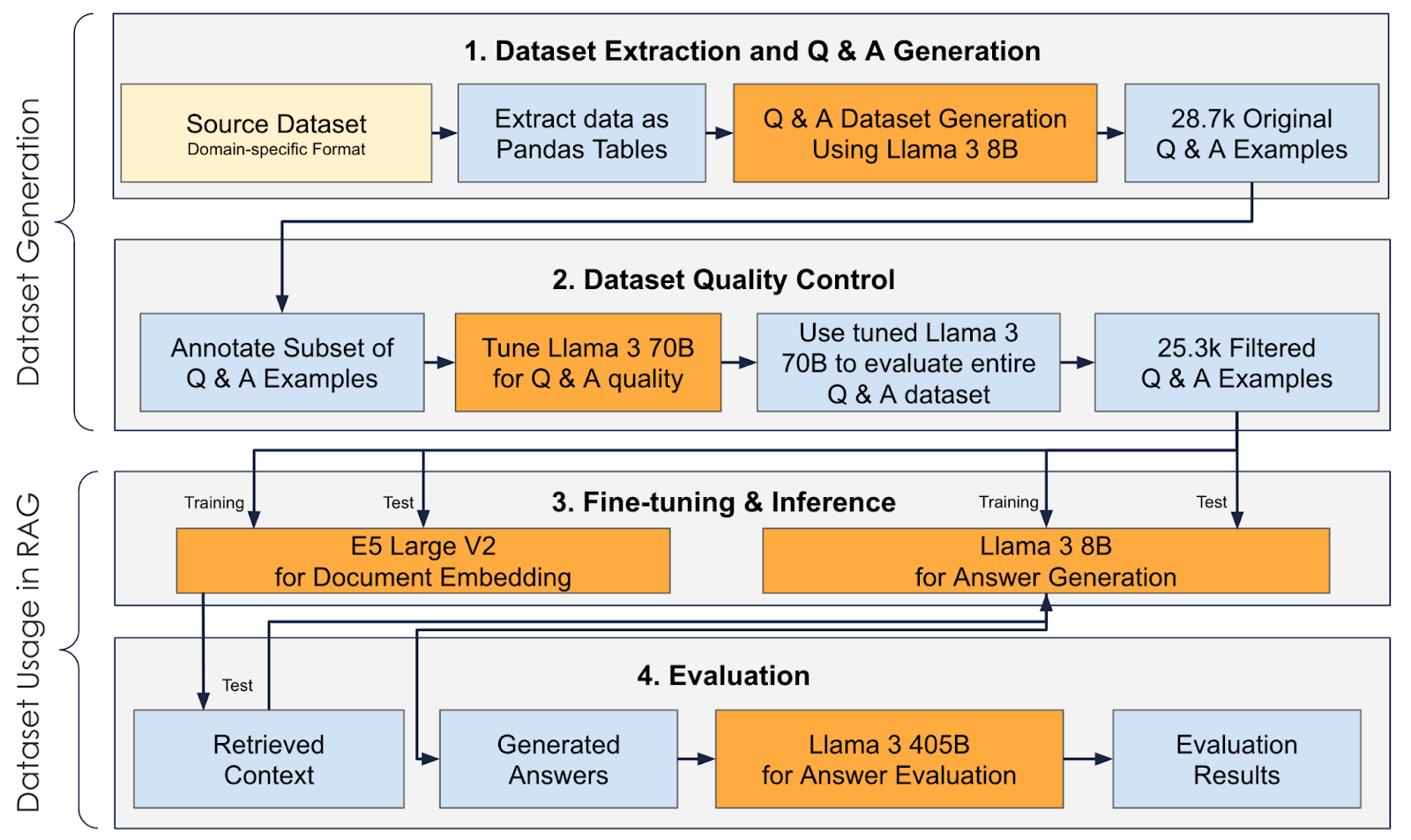
The diagram above describes the end-to-end process from dataset generation to its use in RAG.
Why fine-tune?
Fine-tuning may not be required for many use cases in which the knowledge base does not contain domain-specific jargon. When there is such jargon, however, embeddings and LLMs may not know how to encode them out-of-the box and fine-tuning can help with that. Further, fine-tuning smaller models can achieve higher accuracy than much larger models while providing much higher throughputs (ability to handle more questions per second).
The following results compare the performance of embedding models with and without fine-tuning on a domain-specific dataset that contains cybersecurity jargon:
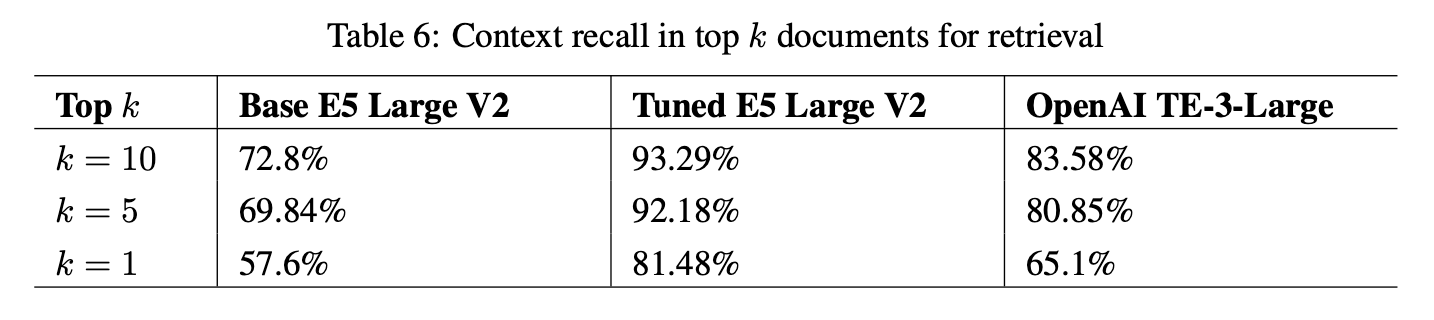
Context recall refers to the models’ ability to encode documents so that relevant documents are returned in the top k results for a given question.
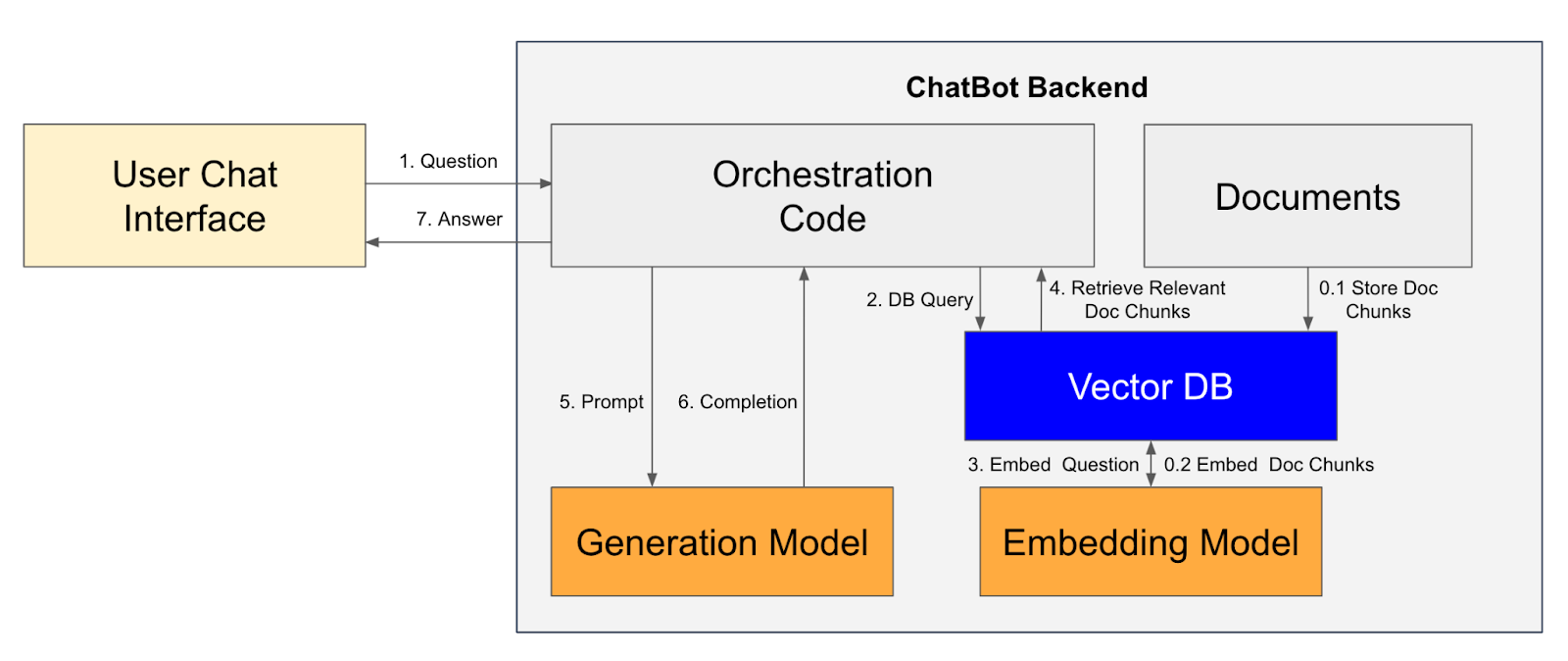
A RAG pipeline combines embedding models for retrieval and LLMs for answer generation using the retrieved context. The steps in the RAG pipeline, backing a chatbot, are described in the following diagram:
The following table presents results for different configurations of a RAG pipeline used on a cybersecurity dataset. The first column leverages SOTA models from OpenAI, such as the Text Embedding 3 Large (TE-3-L) embedding and GPT-4o LLM. The remaining columns have combinations of models that are not tuned (referred to as “Base”) and models that are “Tuned” with rationales (including a “thought” process along with the “answer” to a “question”). “Emb” refers to the E5 V2 Large embedding and “Gen” refers to Llama 3 8B.
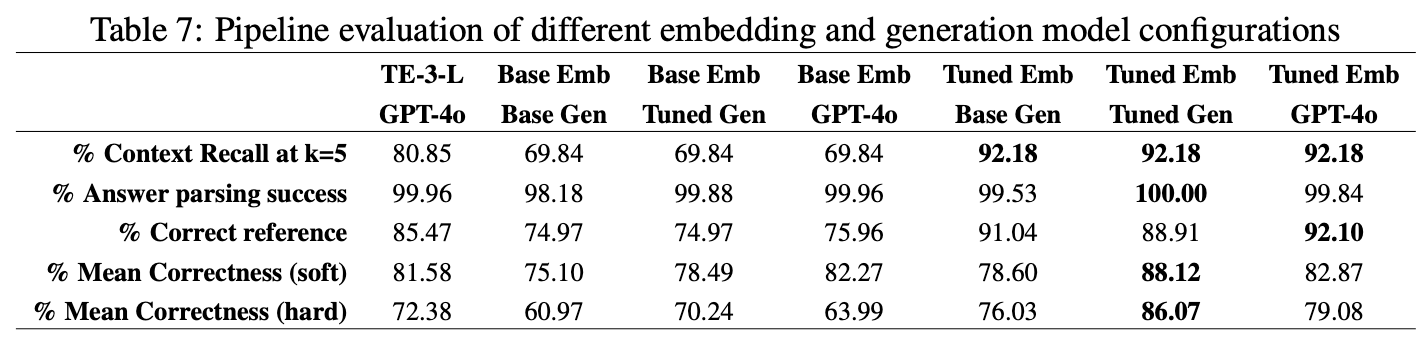
It can be clearly seen from the above results that fine-tuning both the embedding and generation models produces the highest accuracy in retrieval and generated results. It must be noted that the fine-tuned models are many times smaller than the OpenAI models that we are comparing them against, giving them an advantage in throughput in addition to accuracy. In the above table,
- “Answer parsing success” refers to the LLMs’ ability to generate an answer and references in the required format for downstream parsing. Note that fine-tuning the generation LLM ensures perfect alignment with the required format.
- “Correct reference” refers to the model being able to include the right reference to the document that contains the correct answer. GPT-4o performed marginally better here with the help of a tuned open-source embedding.
- “Mean correctness (soft)” refers to the correctness of the model, as determined by Llama 3 405 as a judge, while providing concessions for the failure of the retrieval/embedding component of the pipeline. If the relevant document to the question was not retrieved, then the model must claim to not know the answer. The fine-tuned embedding and generation combination performs the best.
- “Mean correctness (hard)” refers to the correctness of the model, as determined by LLama 3 405 as a judge, regardless of whether the retrieval/embedding component of the pipeline returned irrelevant context. The fine-tuned embedding and generation combination performs the best.
Although the fine-tuned models have not seen the questions used in the evaluation (which are in a hold-out set), they are familiar with the knowledge base of documents and that gives them an edge in answering questions correctly.
The following is an example of an evaluation conducted by Llama 3 405B, which was prompted to provide a score and a reason for giving that score:

In the above example, all the embeddings found the correct document (d*) in the retrieval component and ranked it in the top 3. GPT-4o generated a less accurate answer than the tuned generation Llama 3 8B. Like GPT-4o, even the base Llama 3 8B failed to mention that “testing and debugging" are purposes of the ‘Office Test' registry key. That is despite the fact that the name of the key implies the purpose and the purpose is explicitly stated in the document. That highlights that tuning the generation model with rationales can help improve reasoning.
In summary, smaller, open-source models can be leveraged and fine-tuned to outperform SOTA proprietary models, both in terms of speed and accuracy.
For more details on the setup of the above results, please refer to the following paper: AttackQA: Development and adoption of a dataset for assisting cybersecurity operations using fine-tuned and open-source LLMs.