INTRODUCTION
Using tools can extend the capabilities of LLMs’ to access knowledge beyond their training data. As an example, LLMs often underperform in math compared to text generation capabilities. However, math is a well-solved problem with established tools like calculators. Rather than investing significant time in training LLMs for math at various difficulty levels, teaching them to use calculators is a more efficient and scalable approach. Similarly, such approaches can also be extended to enable LLMs to manipulate software and applications via a natural language interface. Enterprises can greatly benefit from this technology, but for security purposes they require a fully controllable LLM integrated with their software, rather than exposing their APIs to an external LLM provider, especially when the data and use case is sensitive.
Open source LLMs are getting stronger by the day on general NLP tasks. The latest models, such as Llama 2 released by Meta, also went through an extensive alignment phase after pre-training. This makes them performant in a variety of use cases. However, little understanding exists on their ability to manipulate API functions with natural language inputs. To understand this, we curated a comprehensive benchmark, ToolBench, for the community to evaluate the LLM capability of using software to tackle real-world tasks. This will enable users to gain a better understanding of where the performance gaps are between open source and proprietary models, facilitating their selection and adoption of open source models.
At SambaNova, we consistently strive to collaborate with the open source community by enabling open source models on our platform, as the community is moving at an incredibly fast pace and their innovation can bring critical value for the end customers. Thus, we are motivated to study where the gaps are and propose practical and scalable methods to overcome the weaknesses of tool manipulation on those open source models. In particular, we found that using the three following techniques can greatly reduce the gap between open source models and proprietary models:
- Model Alignment with Programmatic Data Curation,
- In-Context Learning with Demonstration Examples
- Generation Regulation with System Prompts.
These methods take about one developer day to curate data for a given tool and they can greatly reduce the accuracy gap between open source models and proprietary models like GPT-4. We demonstrate that our techniques can boost leading open-source LLMs by up to a 90% success rate, demonstrating capabilities either surpassing or closely following GPT-4 in 4 out of 8 ToolBench tasks.
BENCHMARKING LLMS ON TOOL USAGE ABILITIES
Here at SambaNova, we built a comprehensive benchmark, ToolBench, to study where the exact gap is between open source and closed source models and evaluated the open source model performance with the enhancements. ToolBench contains eight real world tasks covering APIs in Shell, Python and text format. They range from simple tasks that require only one API call per task to harder ones that require multiple step interactions within the environment, with multiple API calls per step.
We benchmark a wide variety of open source and proprietary models and report their average accuracy on tasks from the ToolBench. Our initial results indicate proprietary models (black) are significantly better than open source models (blue). The recently released LLaMA 2 – 70b is the best among all of the open source models.
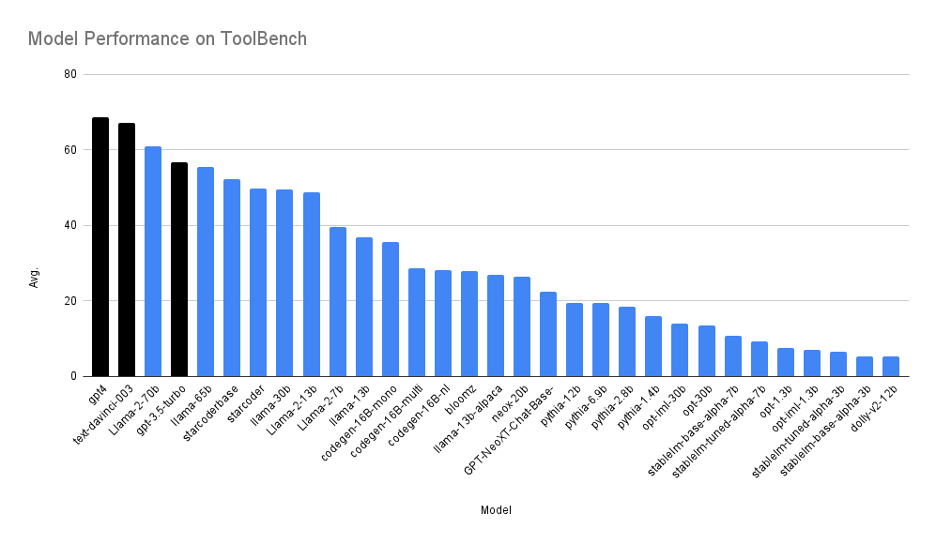
Figure 1. Average toolbench scores for proprietary and open source models. All the proprietary models are benchmarked in May 2023. All the models are evaluated in the 3-shot manner. The benchmark results and detailed breakdown can be found in the Toolbench leaderboard on HuggingFace.
TECHNIQUES DEEP DIVE
We observe that open source LLMs often face difficulty in (1) API selection, (2) API argument population, and (3) generating legitimate and executable code. Thus, we revisited three techniques from the LLM literature and adapted them to address the aforementioned challenges using a practical amount of human supervision.
MODEL ALIGNMENT WITH PROGRAMMATIC DATA CURATION
We fine-tuned the model with programmatic data that is generated by randomly filling values into a set of predefined hand-crafted templates. It is not necessary for the templates to cover all the combinations of API functions. In practice, it’s good enough to have only O(n) templates to cover all API functions as well as the popular use cases.
The picture below is an example of programmatic data generation:
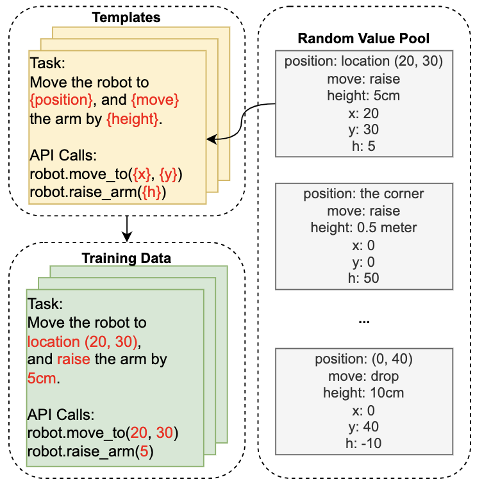
Figure 2. Programmatic training data generation using templates and random values
IN-CONTEXT LEARNING WITH DEMONSTRATION EXAMPLES
We retrieve the top-k relevant demonstration examples for each given goal and place them in the prompt. It’s not necessary for the examples to cover all the combinations of API functions. In practice, it’s good enough to have only O(n) examples to cover all API functions as well as the popular use cases. Accuracy improves drastically with each example, but it also saturates quickly.
The picture below shows the model accuracy on a ToolBench task with different numbers of demonstration examples in the prompt.
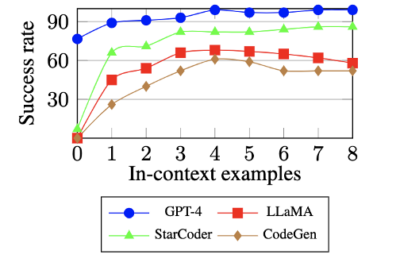
Figure 3: In-context demonstration can improve both closed and open-source models on Home Search, a tool for browsing houses on sale.
GENERATION REGULATION WITH SYSTEM PROMPTS
System prompts are widely used in chat-oriented LLM systems to control the natural language style of the generated response. Here, we want to use the same idea to control the output to be API function calls, without using additional verbose text. This only needs to be developed once per task.
The image below shows an example of the system prompt we used for ToolBench:

Figure 4: System prompt with guidelines to only generate code in a desired format. Red parts are populated with real data for each test case during inference.
RESULTS
The below table reflects the capability gap in tool manipulation between proprietary and open source LLMs in the out-of-the-box zero-shot setting. Using model alignment, the in-context demonstration retriever and the system prompt, open source LLMs attain a significant boost in success rate. GPT-4 is enhanced with the retriever and system prompt. Tabletop is only evaluated in the few-shot fashion.
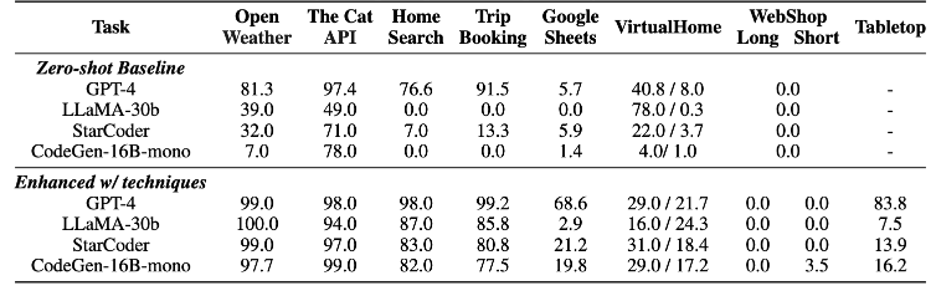
We conducted thorough experiments of different models on the ToolBench. We observed that there is a noticeable performance gap between the API-gated GPT-4 and open-source models in the out-of-the-box zero-shot setting. However, all the models have shown improvements from the techniques, indicating that the techniques are effective in improving model performance with tool use. Further, after applying the combined enhancement techniques, the open-source models achieve competitive or better accuracy on 4 out of 8 tasks compared to GPT-4. Note that challenges still remain for the tasks that require advanced reasoning (e.g. manipulating GoogleSheets), which we will work with the open-source community to close in the future.
CONCLUSION
We studied ways to enhance open-source LLMs to compete with leading closed LLM APIs in tool manipulation with practical amounts of human supervision. Having a tool manipulation system is key to optimizing workflows in a variety of enterprise scenarios. If you are interested in reading more about this work, you can read this paper on arxiv and find the associated code on github. You can also track how the latest models are doing on the leaderboard at the Hugging Face leaderboard. If you have any questions about this work, come find us on SambaNova discord and join the toolbench channel.